당신은 주제를 찾고 있습니까 “자바 xml 파싱 – 자바 온라인 교육 | Java DOM Parser를 사용하여 XML 구문 분석“? 다음 카테고리의 웹사이트 https://kk.taphoamini.com 에서 귀하의 모든 질문에 답변해 드립니다: https://kk.taphoamini.com/wiki. 바로 아래에서 답을 찾을 수 있습니다. 작성자 Firebox Training 이(가) 작성한 기사에는 조회수 200,612회 및 좋아요 1,894개 개의 좋아요가 있습니다.
Table of Contents
자바 xml 파싱 주제에 대한 동영상 보기
여기에서 이 주제에 대한 비디오를 시청하십시오. 주의 깊게 살펴보고 읽고 있는 내용에 대한 피드백을 제공하세요!
d여기에서 자바 온라인 교육 | Java DOM Parser를 사용하여 XML 구문 분석 – 자바 xml 파싱 주제에 대한 세부정보를 참조하세요
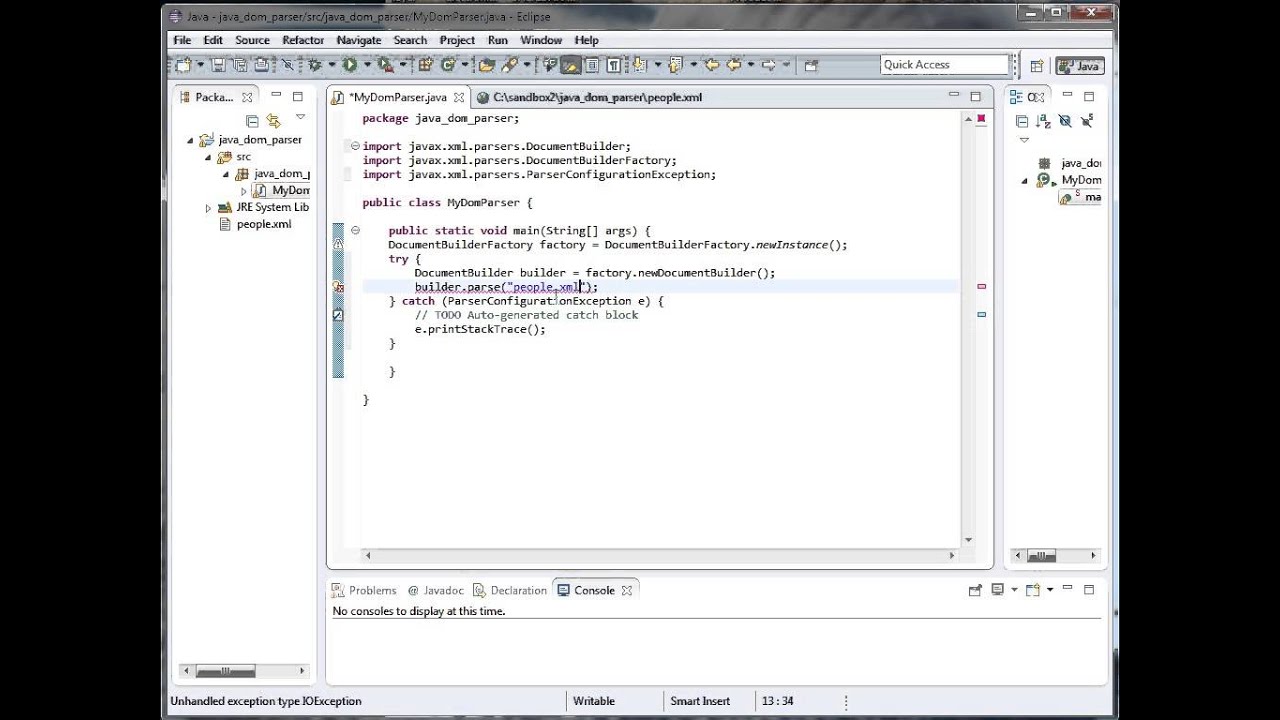
Online Java Courses. This Java XML video tutorial demonstrates how to parse an XML file using the Java programming language. We are using a DOM (Document Object Model) parser to find XML elements and print their values to the screen. You can get complete Java training online with instructor led online training with Firebox. https://www.fireboxtraining.com/java
자바 xml 파싱 주제에 대한 자세한 내용은 여기를 참조하세요.
[Java] XML파일과 자바(Java)로 파싱(parsing)하기
ParserConfigurationException; import org.w3c.dom.Document; // xml 파싱 빌드업 DocumentBuilderFactory factory = DocumentBuilderFactory.
Source: reinvestment.tistory.com
Date Published: 3/12/2021
View: 5796
자바. XML 파싱(Parsing)하여 API데이터 가져오기 – 네이버 블로그
프로젝트를 진행하면서 XML을 파싱하여 데이터를 추출해야할 일이 생겨서, 이번에 열심히 구글링을 통해 알아낸 XML parsing기법을 소개하려고 한다.
Source: m.blog.naver.com
Date Published: 6/24/2022
View: 397
[Java] 자바에서 XML을 파싱하는 방법 – DOM, SAX
– 장점: 구현과 구조변경이 쉽다. 코드 예시. 파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다. import java.io.File …
Source: scshim.tistory.com
Date Published: 3/26/2021
View: 4906
Java XML Parser – DigitalOcean
DOM Parser is the easiest java xml parser to learn. DOM parser loads the XML file into memory and we can traverse it node by node to parse the …
Source: www.digitalocean.com
Date Published: 10/24/2022
View: 8210
[JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기 – 메리
[JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기 · DocumentBuilderFactor : 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 …Source: mchch.tistory.com
Date Published: 5/25/2022
View: 7887
[Java] XML 파싱 – 팡트루야 – 티스토리
XML 파싱이라는 작업이 워낙에 일반적이다보니 Java는 XML 파서를 내장하고 있습니다. 2. 내장 라이브러리를 사용한 XML 파싱 예제. 아래와 같은 구조의 …
Source: pangtrue.tistory.com
Date Published: 3/20/2022
View: 659
자바 Xml 파싱 | [Swtt] Xml문서의 구조와 Parsing 최근 답변 146개
자바 xml 파싱 주제에 대한 자세한 내용은 여기를 참조하세요. [Java] XML파일과 자바(Java)로 파싱(parsing)하기.
Source: you.giarevietnam.vn
Date Published: 12/2/2021
View: 9417
Java DOM Parser – Parse XML Document – Tutorialspoint
Steps to Using JDOM · Import XML-related packages. · Create a SAXBuilder. · Create a Document from a file or stream · Extract the root element · Examine attributes …
Source: www.tutorialspoint.com
Date Published: 3/26/2021
View: 1738
자바 XML 처리 – DOM 파서(1) XML 읽기 – 개꼬 [: 개발하는 꼬바리]
DOM 파서는 XML을 파싱 하여 메모리 상에 XML 구조에 대응하는 객체의 트리를 유지합니다. 자바에서는 DOM 트리를 찾아 임의의 노드에 접근하는 것을 …
Source: byul91oh.tistory.com
Date Published: 3/4/2021
View: 6202
[Java] 자바를 이용한 XML 파싱(SAX parser 활용)
이전 포스팅에서 자바에서 XML을 파싱하는 방법으로 SOX Parser와 DOM Parser가 있다는 것을 설명하였다.
Source: sangwoo0727.github.io
Date Published: 5/3/2022
View: 456
주제와 관련된 이미지 자바 xml 파싱
주제와 관련된 더 많은 사진을 참조하십시오 자바 온라인 교육 | Java DOM Parser를 사용하여 XML 구문 분석. 댓글에서 더 많은 관련 이미지를 보거나 필요한 경우 더 많은 관련 기사를 볼 수 있습니다.
주제에 대한 기사 평가 자바 xml 파싱
- Author: Firebox Training
- Views: 조회수 200,612회
- Likes: 좋아요 1,894개
- Date Published: 2014. 5. 7.
- Video Url link: https://www.youtube.com/watch?v=HfGWVy-eMRc
[Java] XML파일과 자바(Java)로 파싱(parsing)하기
728×90
반응형
xml예시 파일
서울
한국이 25
java로 xml파일 parsing 하기
XML 파일에서 데이터를 가져오는 절차는 HTML 파일에서 데이터를 가져오는 절차와 유사합니다.
HTML에서 데이터를 가져오거나 수정하기 위해서는 필요한 태그를 인식해줄 필요가 있습니다.
예를 들어, document.getElementById(“가져올 태그의 Id”) 명령어를 이용해서 특정 아이디를 가진 태그를 인식할 수 있습니다.
이처럼 xml파일 역시 태그를 인식하기 위해서 필요한 절차는 문서의 자체 객체인 document를 가져오는 것입니다.
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; // xml 파싱 빌드업 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); // xml 파일을 document로 파싱하기 Document document = builder.parse(“xml/sample.xml”);
xml 파일의 위치는 원하는 상대 경로 혹은 절대 경로를 통해서 가져옵니다.
xml 파일 위치 예시
이제 자바가 xml 파일의 document를 가지고 와서 태그들을 인식할 준비가 되었습니다.
태그라는 것이 결국 document안에 있는 요소(element)이기 때문에 이 Element를 가져와야 합니다.
getDocumentElement() 메서드를 사용하면 가장 첫번째 요소(root 요소)를 가져 올 수 있습니다.
import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; // root 요소 가져오기 Element root = document.getDocumentElement(); // root 요소 확인 : 첫 태그 sample System.out.println(root.getNodeName()); // root 요소의 첫번째 노드는 #Text Node firstNode = root.getFirstChild(); // 다음 노드는 customer Node customer = firstNode.getNextSibling(); // customer 요소 안의 노드 리스트 NodeList childList = customer.getChildNodes();
root요소가
태그이기 때문에 첫번째 Element인 root를 가져와서 getNodeName() 메소드를 이용해서 리턴된 문자열(String)을 출력하면 “sample”이라는 값을 얻을 수 있습니다. getFirstChilde() 메소드를 사용하면 해당 요소의 첫 번째 있는 노드를 가져와서 리턴합니다.
이때, root라는 변수에 저장된
태그의 첫 번째 node가 태그가 아닌 #Test로 표시되는데 이는 xml파일의 빈 공백을 노드로 인식하기 때문입니다. 태그와 태그 사이의 공백을 하나의 노드로 인식하기 때문에 공백의 길이에 상관없이 하나의 노드가 됩니다.
getNextSibiling() 메서드를 이용하면 계속해서 해당 요소의 다음 노드를 리턴하게 됩니다.
첫 공백 노드에서 다음 노드인
태그 노드에 오게 되면 getChildeNodes() 메서드를 이용해서 태그 안의 노드들을 리스트로 리턴 받을 수 있습니다. 이제 customer 태그 안에 있는 태그들의 모든 데이터를 가져올 수 있습니다.
for(int i = 0; i < childList.getLength(); i++) { Node item = childList.item(i); if(item.getNodeType() == Node.ELEMENT_NODE) { // 노드의 타입이 Element일 경우(공백이 아닌 경우) System.out.println(item.getNodeName()); System.out.println(item.getTextContent()); } else { System.out.println("공백 입니다."); } } --출력 결과-- 공백입니다. name 한국이 공백 입니다. age 25 공백 입니다. address 서울 공백 입니다. 가져온 요소들의 집합으로 이루어진 리스트에서. item(index) 메서드를 이용해서 각각의 요소들을 가져올 수 있습니다. 위와 마찬가지로 첫 번째 요소는 공백을 요소로 가져오고 태그, 공백을 반복하면서 리스트에 저장되어있습니다. 이제 getTextContext() 메서드를 사용하면 태그 사이의 우리가 필요로 하는 데이터를 가져올 수 있습니다. 728x90 반응형
#자바. XML 파싱(Parsing)하여 API데이터 가져오기
프로젝트를 진행하면서 XML을 파싱하여 데이터를 추출해야할 일이 생겨서, 이번에 열심히 구글링을 통해 알아낸 XML parsing기법을 소개하려고 한다.
현재 정부3.0 이후로, 대부분의 공공데이터를 손쉽게 일반 사용자들도 이용할 수 있게 되었다. 그리고 이러한 데이터들은 주로 API를 통해 이뤄져 있는데, 오늘은 XML파싱을 통하여 API형태의 데이터를 추출하는 방법에 대해 알아보려고 한다.
여기서 사용할 API는 금감원(금융감독원)에서 제공하는 금융상품데이터 API이다. 이 API에는 금융회사, 금융상품명, 이율, 거래유지수, 연평균수익률 등의 정보가 담겨있다.
[Java] 자바에서 XML을 파싱하는 방법 – DOM, SAX
반응형
XML은 w3c에서 개발된 마크업 언어로, 여러 종류의 데이터를 기술하는 데 사용할 수 있다.
예시 – 주식 정보를 나타내는 XML
Citibank 100 1000 Axis bank 90 2000 이러한 XML 문서를 파싱하는 방법에는 대표적으로 DOM과 SAX가 존재한다. 이 글에서는 두 방식의 차이와 각 방식의 자바 코드 예시를 제공한다.
DOM
· XML을 트리 형태의 데이터로 만든 후, 해당 데이터를 가공하는 방식으로 파싱을 진행한다.
· XML 문서를 메모리에 모두 로드한 후 파싱한다.
– 단점: 메모리를 많이 사용한다.
– 장점: 구현과 구조변경이 쉽다.
코드 예시
파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다.
import java.io.File; import java.nio.file.Paths; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class DOMParserExam { public static void main(String[] args){ try { // 파일 경로 File stocks = new File(Paths.get(“”).toAbsolutePath()+”/src/main/java/숙제20211207/Stocks.xml”); // 파일 읽기 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); Document doc = dBuilder.parse(stocks); doc.getDocumentElement().normalize(); System.out.println(“파일출력”); // 읽어들인 파일 불러오기 NodeList nodes = doc.getElementsByTagName(“stock”); for (int k = 0; k < nodes.getLength(); k++) { Node node = nodes.item(k); if (node.getNodeType() == Node.ELEMENT_NODE) { Element element = (Element) node; System.out.println("Stock Symbol: " + getValue("symbol", element)); System.out.println("Stock Price: " + getValue("price", element)); System.out.println("Stock Quantity: " + getValue("quantity", element)); } } } catch (Exception ex) { ex.printStackTrace(); } } private static String getValue(String tag, Element element) { NodeList nodes = element.getElementsByTagName(tag).item(0).getChildNodes(); Node node = (Node) nodes.item(0); return node.getNodeValue(); } } SAX · XML 문서를 라인단위로 체크하면서 파싱하는 방법이다. · 이러한 이유로 XML 데이터를 모두 메모리에 올려 놓지 않고 파싱을 진행한다. - 장점: 메모리를 사용하는 공간이 DOM에 비하여 작다. - 단점: 구현과 구조 변경이 어렵다. · 핸들러를 따로 구현하여 발생한 이벤트를 변수에 저장 활용하는 방식을 사용한다. 코드 예시 파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다. import lombok.Getter; import lombok.Setter; import lombok.ToString; @ToString @Getter @Setter public class Stock { private String symbol; private int price; private int quantity; } import java.util.ArrayList; import java.util.List; import org.xml.sax.Attributes; import org.xml.sax.helpers.DefaultHandler; public class StocksSaxHandler extends DefaultHandler { //파싱한 Stock객체를 넣을 리스트 private List
stockList; //파싱한 Stock 객체 private Stock stock; //character 메소드에서 저장할 문자열 변수 private String str; public StocksSaxHandler() { stockList = new ArrayList<>(); } public void startElement(String uri, String localName, String name, Attributes att) { //시작 태그를 만났을 때 발생하는 이벤트 if(name.equals(“stock”)) { stock = new Stock(); stockList.add(stock); } } public void endElement(String uri, String localName, String name) { //끝 태그를 만났을 때, if(name.equals(“symbol”)) { stock.setSymbol(str); }else if(name.equals(“price”)) { stock.setPrice(Integer.parseInt(str)); }else if(name.equals(“quantity”)) { stock.setQuantity(Integer.parseInt(str)); } } public void characters(char[] ch, int start, int length) { //태그와 태그 사이의 내용을 처리 str = new String(ch,start,length); } public List getStockList(){ return stockList; } public void setStockList(List stockList) { this.stockList=stockList; } } import java.io.File; import java.nio.file.Paths; import java.util.List; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; public class SAXParserExam { public static void main(String[] args) { File stocks = new File(Paths.get(“”).toAbsolutePath()+”/src/main/java/숙제20211207/Stocks.xml”); SAXParserFactory factory = SAXParserFactory.newInstance(); try { SAXParser parser = factory.newSAXParser(); StocksSaxHandler handler = new StocksSaxHandler(); parser.parse(stocks, handler); List
list = handler.getStockList(); for(Stock stock:list) { System.out.println(stock); } }catch(Exception e) { e.printStackTrace(); } } } 출처
https://humble.tistory.com/23
https://sangwoo0727.github.io/java/JAVA-29_SAXParser/
반응형
Java XML Parser
While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Java XML parser is used to work with xml data. XML is widely used technology to transport or store data. That’s why there are many java xml parsers available.
Java XML Parser
Some of the commonly used java xml parsers are;
DOM Parser SAX Parser StAX Parser JAXB
There are some other APIs also available for XML parsing in java, for example JDOM and JiBX . This java xml parser tutorial is aimed to explore different kinds of XML processing API’s and to learn some common tasks we need to perform with XML such as read, write and edit.
Java XML Parser – DOM
DOM Parser is the easiest java xml parser to learn. DOM parser loads the XML file into memory and we can traverse it node by node to parse the XML. DOM Parser is good for small files but when file size increases it performs slow and consumes more memory.
Read XML File This article shows how to use DOM Parser to parse XML file to Object. Write XML File This article explains how to use DOM Parser to write Object data to XML file. Edit XML File DOM Parser can be used to edit XML data also. This article shows how to add elements, remove elements, edit element values, edit attributes in an XML document using DOM Parser.
Java XML Parser – SAX
Java SAX Parser provides API to parse XML documents. SAX Parsers are different than DOM parser because it doesn’t load complete XML into memory and read xml document sequentially. It’s an event based parser and we need to implement our Handler class with callback methods to parse XML file. It’s more efficient than DOM Parser for large XML files in terms of time and memory usage.
Read XML File Learn how to create our Callback Handler class to read XML file to list of Objects using SAX Parser.
StAX Java XML Parser
Java Streaming API for XML (Java StAX) provides implementation for processing XML in java. StAX consists of two sets of API – cursor based API and iterator based API. I have covered this java xml parser extensively in different posts.
Read XML File Using StAX Iterator API In this tutorial we will learn how to read XML iteratively using Java StAX ( XMLEventReader ). Write XML File Using StAX Iterator API In this tutorial we will see how we can write XML file in java using StAX Iterator based API ( XMLEventWriter ). Read XML File Using StAX Cursor API This article shows how to use StAX Cursor API ( XMLStreamReader ) to read XML data to Object. Write XML File Using StAX Cursor API Java StAX Cursor API is very straight forward in creating XML and outputting it. We need to create XMLStreamWriter object and write data into it. This tutorial explains it in detail with example.
Java XML Parser – JDOM
JDOM provides a great Java XML parser API to read, edit and write XML documents easily. JDOM provides wrapper classes to chose your underlying implementation from SAX Parser, DOM Parser, STAX Event Parser and STAX Stream Parser. Benefit of using JDOM is that you can switch from SAX to DOM to STAX Parser easily, you can provide factory methods to let client application chose the implementation.
JDOM Read XML File In this tutorial, we will learn how to read XML file to Object using JDOM XML Parser. JDOM Write XML File In this tutorial we will learn how to write XML file in Java using JDOM. JDOM Document provides methods to easily create elements and attributes. XMLOutputter class can be used to write the Document to any OutputStream or Writer object. JDOM Edit XML File JDOM provides very neat way to manipulate XML files, using JDOM is very easy and the code looks clean and readable. In this tutorial we will learn how to add element, remove element, edit element value and edit attribute value.
Java XML Parser – JAXB
Java Architecture for XML Binding (JAXB) provides API for converting Object to XML and XML to Object easily. JAXB was developed as a separate project but it was used widely and finally became part of JDK in Java 6.
JAXB Tutorial Using JAXB is very easy and it uses annotations. We need to annotate Java Object to provide instructions for XML creation and then we have to create Marshaller to convert Object to XML. Unmarshaller is used to convert XML to java Object. In this tutorial we will learn most widely used JAXB annotations and how to convert a Java Object to XML (Marshalling) and XML to Java Object (Unmarhsalling).
Java XML Parser – JiBX
JiBX is a very powerful framework for converting XML data to java object and vice versa. It is very useful in applications integration where XML is the format for data transfer, for example, Web Services and Legacy Systems Integration based on Message Oriented Model (MOM).
JiBX Tutorial There are many frameworks available for XML transformation such as JAXB and XMLBeans but JiBX differs in the approach for XML binding and transformation process. JiBX performs these tasks via utility classes generated at compile time via ant scripts. This approach reduces the processing time by moving away from the traditional two-step process with other parsers to a single step.
XPath
XPath provides syntax to define part of an XML document. XPath Expression is a query language to select part of the XML document based on the query String. Using XPath Expressions, we can find nodes in any xml document satisfying the query string.
XPath Tutorial javax.xml.xpath package provides XPath support in Java. To create XPathExpression, XPath API provide factory methods. In this tutorial we will use XPath query language to find out elements satisfying given criteria.
Miscellaneous Java XML parser tasks
Generate Sample XML from XSD in Eclipse If you work on web services, you must have been using XSD’s and to test the webservice, you need to generate XML from XSD file. Eclipse provide a very easy way to generate XML from XSD. Validate XML against XSD Java XML Validation API can be used to validate XML against an XSD. javax.xml.validation.Validator class is used in this tutorial to validate xml file against xsd file. Java XML Property File Usually we store configurations parameters for java applications in a property file. In java property file can be a normal property file with key-value pairs or it can be an XML file also. In this example, we will learn how to write property XML file and then read properties from XML property files. SOAP XML Soap is an Xml based transport protocol. Soap stands for Simple Object Access Protocol. Soap is a lightweight mechanism for exchanging structured and typed information. As it is XML based so it is language and platform independent. In this tutorial you will learn about SOAP XML and how can we create it using Liquid XML Studio software. Format XML Document A utility class with methods for pretty printing XML and converting XML Document to String and String to XML document. Convert Document to String and String to Document Sometimes while programming in java, we get String which is actually an XML and to process it, we need to convert it to XML Document (org.w3c.dom.Document). Also for debugging purpose or to send to some other function, we might need to convert Document object to String. Two utility methods to convert String to XML Document and XML Document to String.
I will be adding more java XML parser tutorials here as and when I post more, so don’t forget to bookmark it for future use.
[JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기
반응형
XML 문서
00 NORMAL_CODE
2 55 0.002 2 57 0.002 10 1 23 DocumentBuilderFactor : 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 수 있는 팩토리 API를 정의합니다.
: 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 수 있는 팩토리 API를 정의합니다. DocumentBuilder : 현재 설정되어 있는 파라미터를 사용해 새로운 DocumentBuilder 인스턴스를 작성합니다.
이 클래스의 인스턴스를 취득하면, 다양한 입력 소스로부터 XML 문서를 구문 분석 할 수 있습니다. 이러한 입력 소스에는 InputStream, File, URL 및 SAX InputSource가 있습니다.
: 현재 설정되어 있는 파라미터를 사용해 새로운 DocumentBuilder 인스턴스를 작성합니다. 이 클래스의 인스턴스를 취득하면, 다양한 입력 소스로부터 XML 문서를 구문 분석 할 수 있습니다. 이러한 입력 소스에는 InputStream, File, URL 및 SAX InputSource가 있습니다. Document : HTML 문서 또는 XML 문서 전체를 나타냅니다.
XML 파싱 및 태그의 값 가져오기
//XML 요청 url String url = “http://api.adfafadsfasdfadf”; //XML 파싱 DocumentBuilderFactory dbFactoty = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactoty.newDocumentBuilder(); Document doc = dBuilder.parse(url); //item이라는 태그의 element들 가져오기 NodeList nList = doc.getElementsByTagName(“item”); Node nNode = nList.item(0); if (nNode.getNodeType() == Node.ELEMENT_NODE) { Element eElement = (Element) nNode; getTagValue(“so2Value”, eElement); }
XML 파싱 및 내용 출력하기
//XML문서 요청 url String url = “http://api.adfafadsfasdfadf”; //XML 파싱 DocumentBuilderFactory dbFactoty = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactoty.newDocumentBuilder(); Document doc = dBuilder.parse(url); //XML을 Strig으로 출력 Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.setOutputProperty(OutputKeys.ENCODING, “UTF-8”); tf.setOutputProperty(OutputKeys.INDENT, “yes”); Writer out = new StringWriter(); tf.transform(new DOMSource(doc), new StreamResult(out)); System.out.println(out.toString());
반응형
[Java] XML 파싱
1. XML 파싱
JSON이 편리하고 많이 사용되는게 사실이지만, XML 또한 많이 사용되는 것도 사실입니다.
그렇기 때문에, 데이터를 XML로 만드는 것과 XML을 파싱해서 데이터를 이용하는 것 둘 다 할 줄 알아야합니다.
XML 파싱이라는 작업이 워낙에 일반적이다보니 Java는 XML 파서를 내장하고 있습니다.
2. 내장 라이브러리를 사용한 XML 파싱 예제
아래와 같은 구조의 XML 파일이 있다고하겠습니다.
Alsa 25 태그의 값을 가져오고 싶다면 어떻게 해야 할까요? 🤔 Bob 28 public class DemoXmlParser { public void getXmlData(File xmlFile) { // 1. 빌더 팩토리 생성. DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance(); // 2. 빌더 팩토리로부터 빌더 생성 DocumentBuilder builder = builderFactory.newDocumentBuilder(); // 3. 빌더를 통해 XML 문서를 파싱해서 Document 객체로 가져온다. Document document = builder.parse(xmlFile); // 문서 구조 안정화 ? document.getDocumentElement().normalize(); // XML 데이터 중
태그의 내용을 가져온다. NodeList personTagList = document.getElementByTagName(“person”); // 태그 리스트를 하나씩 돌면서 값들을 가져온다. for (int i = 0; i < personTagList.getLength(); ++i) { // 속성 값 가져오기. String name = personTagList.item(i).getAttributes().getNamedItem("sex").getNodeValue(); // 태그의 하위 노드들을 가져온다. ( 여기서 노드는 태그를 의미한다. ) NodeList childNodes = personTagList.item(i).getChildNodes(); for (int j = 0; j < childNodes.getLength(); ++j) { if ("name".equals(childNodes.item(j).getNodeName()) { // do somthing... } if ("age".equals(childNodes.item(j).getNodeName()) { // do somthing... } } } } } 위의 코드를 보면, 파싱할 XML 파일을 Document 객체에 담아옵니다. 이제 이 Document 객체를 가지고 파싱 작업을 진행하는데요, 위에선 Document#getElementByTagName 메서드를 이용해 태그를 리스트의 형태로 들고왔습니다. 가져온 태그 목록을 NodeList 객체에 담았는데 하나의 XML 태그가 하나의 Node 객체에 매핑되기 때문입니다.
자바 Xml 파싱 | [Swtt] Xml문서의 구조와 Parsing 최근 답변 146개
당신은 주제를 찾고 있습니까 “자바 xml 파싱 – [SWTT] xml문서의 구조와 Parsing“? 다음 카테고리의 웹사이트 you.giarevietnam.vn 에서 귀하의 모든 질문에 답변해 드립니다: you.giarevietnam.vn/blog. 바로 아래에서 답을 찾을 수 있습니다. 작성자 Software Tool Time 이(가) 작성한 기사에는 조회수 1,068회 및 좋아요 10개 개의 좋아요가 있습니다.
자바 xml 파싱 주제에 대한 동영상 보기
여기에서 이 주제에 대한 비디오를 시청하십시오. 주의 깊게 살펴보고 읽고 있는 내용에 대한 피드백을 제공하세요!
d여기에서 [SWTT] xml문서의 구조와 Parsing – 자바 xml 파싱 주제에 대한 세부정보를 참조하세요
강의 : 아주대 상현석
xml문서의 구조와 Parsing
자바 xml 파싱 주제에 대한 자세한 내용은 여기를 참조하세요.
[Java] XML파일과 자바(Java)로 파싱(parsing)하기ParserConfigurationException; import org.w3c.dom.Document; // xml 파싱 빌드업 DocumentBuilderFactory factory = DocumentBuilderFactory.
+ 여기를 클릭
Source: reinvestment.tistory.com
Date Published: 9/16/2021
View: 8359
자바. XML 파싱(Parsing)하여 API데이터 가져오기 – 네이버 블로그
프로젝트를 진행하면서 XML을 파싱하여 데이터를 추출해야할 일이 생겨서, 이번에 열심히 구글링을 통해 알아낸 XML parsing기법을 소개하려고 한다.
+ 여기에 더 보기
Source: m.blog.naver.com
Date Published: 6/23/2022
View: 6396
Java에서 XML 파일을 읽는 방법 – Delft Stack
이 기사에서는 DOM Parser , XML Parser , jdom2 , dom4j 등과 같은 일부 라이브러리를 사용하여 XML 파일을 Java 애플리케이션으로 구문 분석하는 …
+ 자세한 내용은 여기를 클릭하십시오
Source: www.delftstack.com
Date Published: 11/18/2021
View: 7057
[JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기 – 메리 [JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기 · DocumentBuilderFactor : 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 …+ 자세한 내용은 여기를 클릭하십시오
Source: mchch.tistory.com
Date Published: 8/20/2022
View: 6937
[Java] 자바에서 XML을 파싱하는 방법 – DOM, SAX– 장점: 구현과 구조변경이 쉽다. 코드 예시. 파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다. import java.io.File …
+ 더 읽기
Source: scshim.tistory.com
Date Published: 7/18/2022
View: 1341
[Java] XML 파싱 – 팡트루야XML 파싱이라는 작업이 워낙에 일반적이다보니 Java는 XML 파서를 내장하고 있습니다. 2. 내장 라이브러리를 사용한 XML 파싱 예제. 아래와 같은 구조의 …
+ 여기를 클릭
Source: pangtrue.tistory.com
Date Published: 4/3/2022
View: 7689
자바 XML 처리 – DOM 파서(1) XML 읽기 – 개꼬 [: 개발하는 꼬바리]
DOM 파서는 XML을 파싱 하여 메모리 상에 XML 구조에 대응하는 객체의 트리를 유지합니다. 자바에서는 DOM 트리를 찾아 임의의 노드에 접근하는 것을 …
+ 여기에 더 보기
Source: byul91oh.tistory.com
Date Published: 10/15/2021
View: 7708
[Java] 자바를 이용한 XML 파싱(SAX parser 활용)이전 포스팅에서 자바에서 XML을 파싱하는 방법으로 SOX Parser와 DOM Parser가 있다는 것을 설명하였다.
+ 더 읽기
Source: sangwoo0727.github.io
Date Published: 1/12/2021
View: 8510
JAVA XML 파싱으로 데이터 가져오기
오늘은 자바 XML 파싱에 대해서 알아보려고 한다. 사실 요즘 XML은 잘 사용하지 않는 편이고 JSON을 많이 사용하지만 XML도 아직까지 많이 남아 있는 …
+ 여기에 표시
Source: nozee.tistory.com
Date Published: 3/27/2022
View: 7041
자바 xml 데이터, 속성 파싱(java xml parsing data, attribute)
안녕하세요. 오랜만에 자바관련 포스팅을 합니다. 나중에도 요긴하게 쓰일거같아 기본 코딩만 해두고 포스팅하려고 합니다. xml 데이터 파싱을 해보 …
+ 여기에 자세히 보기
Source: lee-mandu.tistory.com
Date Published: 9/30/2021
View: 6108
주제와 관련된 이미지 자바 xml 파싱
주제와 관련된 더 많은 사진을 참조하십시오 [SWTT] xml문서의 구조와 Parsing. 댓글에서 더 많은 관련 이미지를 보거나 필요한 경우 더 많은 관련 기사를 볼 수 있습니다.
[SWTT] xml문서의 구조와 Parsing주제에 대한 기사 평가 자바 xml 파싱
Author: Software Tool Time
Views: 조회수 1,068회
Likes: 좋아요 10개
Date Published: 2021. 1. 19.
Video Url link: https://www.youtube.com/watch?v=l-ojrDq6Z-w
[Java] XML파일과 자바(Java)로 파싱(parsing)하기728×90 반응형 xml예시 파일 한국이 25 서울 java로 xml파일 parsing 하기 XML 파일에서 데이터를 가져오는 절차는 HTML 파일에서 데이터를 가져오는 절차와 유사합니다. HTML에서 데이터를 가져오거나 수정하기 위해서는 필요한 태그를 인식해줄 필요가 있습니다. 예를 들어, document.getElementById(“가져올 태그의 Id”) 명령어를 이용해서 특정 아이디를 가진 태그를 인식할 수 있습니다. 이처럼 xml파일 역시 태그를 인식하기 위해서 필요한 절차는 문서의 자체 객체인 document를 가져오는 것입니다. import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; // xml 파싱 빌드업 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); // xml 파일을 document로 파싱하기 Document document = builder.parse(“xml/sample.xml”); xml 파일의 위치는 원하는 상대 경로 혹은 절대 경로를 통해서 가져옵니다. xml 파일 위치 예시 이제 자바가 xml 파일의 document를 가지고 와서 태그들을 인식할 준비가 되었습니다. 태그라는 것이 결국 document안에 있는 요소(element)이기 때문에 이 Element를 가져와야 합니다. getDocumentElement() 메서드를 사용하면 가장 첫번째 요소(root 요소)를 가져 올 수 있습니다. import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; // root 요소 가져오기 Element root = document.getDocumentElement(); // root 요소 확인 : 첫 태그 sample System.out.println(root.getNodeName()); // root 요소의 첫번째 노드는 #Text Node firstNode = root.getFirstChild(); // 다음 노드는 customer Node customer = firstNode.getNextSibling(); // customer 요소 안의 노드 리스트 NodeList childList = customer.getChildNodes(); root요소가 태그이기 때문에 첫번째 Element인 root를 가져와서 getNodeName() 메소드를 이용해서 리턴된 문자열(String)을 출력하면 “sample”이라는 값을 얻을 수 있습니다. getFirstChilde() 메소드를 사용하면 해당 요소의 첫 번째 있는 노드를 가져와서 리턴합니다. 이때, root라는 변수에 저장된 태그의 첫 번째 node가 태그가 아닌 #Test로 표시되는데 이는 xml파일의 빈 공백을 노드로 인식하기 때문입니다. 태그와 태그 사이의 공백을 하나의 노드로 인식하기 때문에 공백의 길이에 상관없이 하나의 노드가 됩니다. getNextSibiling() 메서드를 이용하면 계속해서 해당 요소의 다음 노드를 리턴하게 됩니다. 첫 공백 노드에서 다음 노드인 태그 노드에 오게 되면 getChildeNodes() 메서드를 이용해서 태그 안의 노드들을 리스트로 리턴 받을 수 있습니다. 이제 customer 태그 안에 있는 태그들의 모든 데이터를 가져올 수 있습니다. for(int i = 0; i < childList.getLength(); i++) { Node item = childList.item(i); if(item.getNodeType() == Node.ELEMENT_NODE) { // 노드의 타입이 Element일 경우(공백이 아닌 경우) System.out.println(item.getNodeName()); System.out.println(item.getTextContent()); } else { System.out.println("공백 입니다."); } } --출력 결과-- 공백입니다. name 한국이 공백 입니다. age 25 공백 입니다. address 서울 공백 입니다. 가져온 요소들의 집합으로 이루어진 리스트에서. item(index) 메서드를 이용해서 각각의 요소들을 가져올 수 있습니다. 위와 마찬가지로 첫 번째 요소는 공백을 요소로 가져오고 태그, 공백을 반복하면서 리스트에 저장되어있습니다. 이제 getTextContext() 메서드를 사용하면 태그 사이의 우리가 필요로 하는 데이터를 가져올 수 있습니다. 728x90 반응형 #자바. XML 파싱(Parsing)하여 API데이터 가져오기 프로젝트를 진행하면서 XML을 파싱하여 데이터를 추출해야할 일이 생겨서, 이번에 열심히 구글링을 통해 알아낸 XML parsing기법을 소개하려고 한다. 현재 정부3.0 이후로, 대부분의 공공데이터를 손쉽게 일반 사용자들도 이용할 수 있게 되었다. 그리고 이러한 데이터들은 주로 API를 통해 이뤄져 있는데, 오늘은 XML파싱을 통하여 API형태의 데이터를 추출하는 방법에 대해 알아보려고 한다. 여기서 사용할 API는 금감원(금융감독원)에서 제공하는 금융상품데이터 API이다. 이 API에는 금융회사, 금융상품명, 이율, 거래유지수, 연평균수익률 등의 정보가 담겨있다. Java에서 XML 파일을 읽는 방법 이 기사에서는 DOM Parser , XML Parser , jdom2 , dom4j 등과 같은 일부 라이브러리를 사용하여 XML 파일을 Java 애플리케이션으로 구문 분석하는 방법을 알아 봅니다. XML은 Extensible Markup Language 를 의미합니다. 애플리케이션에서 데이터를 전달하는 데 사용됩니다. 샘플 XML 파일 이 기사에서 읽는 데 사용되는 샘플 XML 파일입니다. Tony Black 100000 Amy Green 200000 Java에서 DocumentBuilderFactory 를 사용하여 XML 파일 읽기 DocumentBuilder 를 사용하여 빌더의 인스턴스를 만든 다음 parse() 메서드를 사용하여 XML 파일을 구문 분석합니다. getElementsByTagName() 메소드는 XML의 각 노드를 가져온 다음 for 루프를 사용하여 노드의 각 하위 노드를 반복합니다. 아래 예를 참조하십시오. Doc Translator: 문서 번역기는… Please enable JavaScript Doc Translator: 문서 번역기는 어떻게 사용합니까? import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class SimpleTesting { public static void main(String[] args) throws ParserConfigurationException, SAXException { try { File file = new File(“company.xml”); DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); Document document = db.parse(file); document.getDocumentElement().normalize(); System.out.println(“Root Element :” + document.getDocumentElement().getNodeName()); NodeList nList = document.getElementsByTagName(“employee”); System.out.println(“—————————-“); for (int temp = 0; temp < nList.getLength(); temp++) { Node nNode = nList.item(temp); System.out.println(" Current Element :" + nNode.getNodeName()); if (nNode.getNodeType() == Node.ELEMENT_NODE) { Element eElement = (Element) nNode; System.out.println("Employee id : " + eElement.getAttribute("id")); System.out.println("First Name : " + eElement.getElementsByTagName("firstname").item(0).getTextContent()); System.out.println("Last Name : " + eElement.getElementsByTagName("lastname").item(0).getTextContent()); System.out.println("Salary : " + eElement.getElementsByTagName("salary").item(0).getTextContent()); } } } catch(IOException e) { System.out.println(e); } } } 출력: Root Element :company ---------------------------- Current Element :employee Employee id : 1001 First Name : Tony Last Name : Black Salary : 100000 Current Element :employee Employee id : 2001 First Name : Amy Last Name : Green Salary : 200000 Java POJO에서 XML 파일 읽기 XML 데이터를 Java 호환 유형으로 가져 오려는 경우 Java POJO를 사용하여 데이터를 읽을 수 있습니다. 여기서는 ArrayList 유형 Employee를 사용하여 add() 메소드를 사용하여 각 노드를 추가 한 다음 for 루프를 사용하여 각 객체를 반복합니다. 아래 예를 참조하십시오. import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class Main { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse(new File("employee.xml")); List employees = new ArrayList<>(); NodeList nodeList = document.getDocumentElement().getChildNodes(); for (int i = 0; i < nodeList.getLength(); i++) { Node node = nodeList.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) { Element elem = (Element) node; String firstname = elem.getElementsByTagName("firstname") .item(0).getChildNodes().item(0).getNodeValue(); String lastname = elem.getElementsByTagName("lastname").item(0) .getChildNodes().item(0).getNodeValue(); Double salary = Double.parseDouble(elem.getElementsByTagName("salary") .item(0).getChildNodes().item(0).getNodeValue()); employees.add(new Employee(firstname, lastname, salary)); } } for (Employee empl: employees) System.out.println(empl.toString()); } } class Employee { private String Firstname; private String Lastname; private double salary; public Employee(String Firstname, String Lastname, double salary) { this.Firstname = Firstname; this.Lastname = Lastname; this.salary = salary; } @Override public String toString() { return "[" + Firstname + ", " + Lastname + ", "+ salary + "]"; } } 출력: [Tony, Black, 100000.0] [Amy, Green, 200000.0] Java에서 jdom2 를 사용하여 XML 파일 읽기 jdom2는 Java 클래스를 사용하여 DOM 구문 분석을 지원하는 라이브러리입니다. SAXBuilder 클래스와 build() 메소드를 사용하여 Document 로 데이터를 가져온 다음 getRootElement() 메소드를 사용하여 요소를 가져옵니다. 아래 예를 참조하십시오. import java.io.File; import java.io.IOException; import java.util.List; import javax.xml.parsers.ParserConfigurationException; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.JDOMException; import org.jdom2.input.SAXBuilder; import org.xml.sax.SAXException; public class Main { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { try { File inputFile = new File("/employee.xml"); SAXBuilder saxBuilder = new SAXBuilder(); Document document = saxBuilder.build(inputFile); System.out.println("Root element :" + document.getRootElement().getName()); Element classElement = document.getRootElement(); List studentList = classElement.getChildren(); System.out.println(“—————————-“); for (int temp = 0; temp < studentList.size(); temp++) { Element student = studentList.get(temp); System.out.println(" Current Element :" + student.getName()); System.out.println("First Name : " + student.getChild("firstname").getText()); System.out.println("Last Name : " + student.getChild("lastname").getText()); System.out.println("Salary : " + student.getChild("salary").getText()); } } catch(JDOMException e) { e.printStackTrace(); } catch(IOException ioe) { ioe.printStackTrace(); } } } 출력: Root element :company ---------------------------- Current Element :employee First Name : Tony Last Name : Black Salary : 100000 Current Element :employee First Name : Amy Last Name : Green Salary : 200000 Java에서 XPath 를 사용하여 XML 파일 읽기 여기서는 XPath 라이브러리를 사용하여 Java에서 XML 파일을 구문 분석합니다. XPathFactory 클래스는 모든 노드를 NodeList 로 컴파일 한 다음 for 루프를 통해 각 자식을 반복하는 데 사용됩니다. 아래 예를 참조하십시오. import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.xpath.XPath; import javax.xml.xpath.XPathConstants; import javax.xml.xpath.XPathExpressionException; import javax.xml.xpath.XPathFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class Main { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { try { File inputFile = new File("/employee.xml"); DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder; dBuilder = dbFactory.newDocumentBuilder(); Document doc = dBuilder.parse(inputFile); doc.getDocumentElement().normalize(); XPath xPath = XPathFactory.newInstance().newXPath(); String expression = "/company/employee"; NodeList nodeList = (NodeList) xPath.compile(expression).evaluate( doc, XPathConstants.NODESET); for (int i = 0; i < nodeList.getLength(); i++) { Node nNode = nodeList.item(i); System.out.println(" Current Element :" + nNode.getNodeName()); if (nNode.getNodeType() == Node.ELEMENT_NODE) { Element eElement = (Element) nNode; System.out.println("First Name : " + eElement .getElementsByTagName("firstname") .item(0) .getTextContent()); System.out.println("Last Name : " + eElement .getElementsByTagName("lastname") .item(0) .getTextContent()); System.out.println("Salary : " + eElement .getElementsByTagName("salary") .item(0) .getTextContent()); } } } catch (ParserConfigurationException e) { System.out.println(e); } catch (SAXException e) { System.out.println(e); } catch (IOException e) { System.out.println(e); } catch (XPathExpressionException e) { System.out.println(e); } } } 출력: Current Element :employee First Name : Tony Last Name : Black Salary : 100000 Current Element :employee First Name : Amy Last Name : Green Salary : 200000 Java에서 DOM4J 를 사용하여 XML 파일 읽기 Dom4j 는 Java에서 XML 파일을 구문 분석 할 수있는 또 다른 라이브러리입니다. SAXReader 클래스의 read() 메소드는 노드를 문서로 읽는 데 사용됩니다. 아래 예를 참조하십시오. import java.io.File; import java.io.IOException; import java.util.List; import javax.xml.parsers.ParserConfigurationException; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; import org.xml.sax.SAXException; public class Main { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { try { File inputFile = new File("employee.xml"); SAXReader reader = new SAXReader(); Document document = reader.read( inputFile ); System.out.println("Root element :" + document.getRootElement().getName()); Element classElement = document.getRootElement(); List nodes = document.selectNodes(“company/employee”); System.out.println(“—————————-“); for (Node node : nodes) { System.out.println(” Current Element :” + node.getName()); System.out.println(“First Name : ” + node.selectSingleNode(“firstname”).getText()); System.out.println(“Last Name : ” + node.selectSingleNode(“lastname”).getText()); System.out.println(“Salary : ” + node.selectSingleNode(“salary”).getText()); } } catch (DocumentException e) { e.printStackTrace(); } } } 출력: [JAVA] XML 파싱 / XML 출력 / XML 변환 / XML 읽기 반응형 XML 문서 00 NORMAL_CODE 2 55 0.002 2 57 0.002 10 1 23 DocumentBuilderFactor : 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 수 있는 팩토리 API를 정의합니다. : 어플리케이션으로 XML 문서로부터 DOM 객체 트리를 생성하는 파서를 취득할 수 있는 팩토리 API를 정의합니다. DocumentBuilder : 현재 설정되어 있는 파라미터를 사용해 새로운 DocumentBuilder 인스턴스를 작성합니다. 이 클래스의 인스턴스를 취득하면, 다양한 입력 소스로부터 XML 문서를 구문 분석 할 수 있습니다. 이러한 입력 소스에는 InputStream, File, URL 및 SAX InputSource가 있습니다. : 현재 설정되어 있는 파라미터를 사용해 새로운 DocumentBuilder 인스턴스를 작성합니다. 이 클래스의 인스턴스를 취득하면, 다양한 입력 소스로부터 XML 문서를 구문 분석 할 수 있습니다. 이러한 입력 소스에는 InputStream, File, URL 및 SAX InputSource가 있습니다. Document : HTML 문서 또는 XML 문서 전체를 나타냅니다. XML 파싱 및 태그의 값 가져오기 //XML 요청 url String url = “http://api.adfafadsfasdfadf”; //XML 파싱 DocumentBuilderFactory dbFactoty = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactoty.newDocumentBuilder(); Document doc = dBuilder.parse(url); //item이라는 태그의 element들 가져오기 NodeList nList = doc.getElementsByTagName(“item”); Node nNode = nList.item(0); if (nNode.getNodeType() == Node.ELEMENT_NODE) { Element eElement = (Element) nNode; getTagValue(“so2Value”, eElement); } XML 파싱 및 내용 출력하기 //XML문서 요청 url String url = “http://api.adfafadsfasdfadf”; //XML 파싱 DocumentBuilderFactory dbFactoty = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactoty.newDocumentBuilder(); Document doc = dBuilder.parse(url); //XML을 Strig으로 출력 Transformer tf = TransformerFactory.newInstance().newTransformer(); tf.setOutputProperty(OutputKeys.ENCODING, “UTF-8”); tf.setOutputProperty(OutputKeys.INDENT, “yes”); Writer out = new StringWriter(); tf.transform(new DOMSource(doc), new StreamResult(out)); System.out.println(out.toString()); 반응형 [Java] 자바에서 XML을 파싱하는 방법 – DOM, SAX 반응형 XML은 w3c에서 개발된 마크업 언어로, 여러 종류의 데이터를 기술하는 데 사용할 수 있다. 예시 – 주식 정보를 나타내는 XML Citibank 100 1000 Axis bank 90 2000 이러한 XML 문서를 파싱하는 방법에는 대표적으로 DOM과 SAX가 존재한다. 이 글에서는 두 방식의 차이와 각 방식의 자바 코드 예시를 제공한다. DOM · XML을 트리 형태의 데이터로 만든 후, 해당 데이터를 가공하는 방식으로 파싱을 진행한다. · XML 문서를 메모리에 모두 로드한 후 파싱한다. – 단점: 메모리를 많이 사용한다. – 장점: 구현과 구조변경이 쉽다. 코드 예시 파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다. import java.io.File; import java.nio.file.Paths; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class DOMParserExam { public static void main(String[] args){ try { // 파일 경로 File stocks = new File(Paths.get(“”).toAbsolutePath()+”/src/main/java/숙제20211207/Stocks.xml”); // 파일 읽기 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); Document doc = dBuilder.parse(stocks); doc.getDocumentElement().normalize(); System.out.println(“파일출력”); // 읽어들인 파일 불러오기 NodeList nodes = doc.getElementsByTagName(“stock”); for (int k = 0; k < nodes.getLength(); k++) { Node node = nodes.item(k); if (node.getNodeType() == Node.ELEMENT_NODE) { Element element = (Element) node; System.out.println("Stock Symbol: " + getValue("symbol", element)); System.out.println("Stock Price: " + getValue("price", element)); System.out.println("Stock Quantity: " + getValue("quantity", element)); } } } catch (Exception ex) { ex.printStackTrace(); } } private static String getValue(String tag, Element element) { NodeList nodes = element.getElementsByTagName(tag).item(0).getChildNodes(); Node node = (Node) nodes.item(0); return node.getNodeValue(); } } SAX · XML 문서를 라인단위로 체크하면서 파싱하는 방법이다. · 이러한 이유로 XML 데이터를 모두 메모리에 올려 놓지 않고 파싱을 진행한다. - 장점: 메모리를 사용하는 공간이 DOM에 비하여 작다. - 단점: 구현과 구조 변경이 어렵다. · 핸들러를 따로 구현하여 발생한 이벤트를 변수에 저장 활용하는 방식을 사용한다. 코드 예시 파싱할 xml 파일은 위의 stock 정보를 갖는 xml로 한다. import lombok.Getter; import lombok.Setter; import lombok.ToString; @ToString @Getter @Setter public class Stock { private String symbol; private int price; private int quantity; } import java.util.ArrayList; import java.util.List; import org.xml.sax.Attributes; import org.xml.sax.helpers.DefaultHandler; public class StocksSaxHandler extends DefaultHandler { //파싱한 Stock객체를 넣을 리스트 private List stockList; //파싱한 Stock 객체 private Stock stock; //character 메소드에서 저장할 문자열 변수 private String str; public StocksSaxHandler() { stockList = new ArrayList<>(); } public void startElement(String uri, String localName, String name, Attributes att) { //시작 태그를 만났을 때 발생하는 이벤트 if(name.equals(“stock”)) { stock = new Stock(); stockList.add(stock); } } public void endElement(String uri, String localName, String name) { //끝 태그를 만났을 때, if(name.equals(“symbol”)) { stock.setSymbol(str); }else if(name.equals(“price”)) { stock.setPrice(Integer.parseInt(str)); }else if(name.equals(“quantity”)) { stock.setQuantity(Integer.parseInt(str)); } } public void characters(char[] ch, int start, int length) { //태그와 태그 사이의 내용을 처리 str = new String(ch,start,length); } public List getStockList(){ return stockList; } public void setStockList(List stockList) { this.stockList=stockList; } } import java.io.File; import java.nio.file.Paths; import java.util.List; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; public class SAXParserExam { public static void main(String[] args) { File stocks = new File(Paths.get(“”).toAbsolutePath()+”/src/main/java/숙제20211207/Stocks.xml”); SAXParserFactory factory = SAXParserFactory.newInstance(); try { SAXParser parser = factory.newSAXParser(); StocksSaxHandler handler = new StocksSaxHandler(); parser.parse(stocks, handler); List list = handler.getStockList(); for(Stock stock:list) { System.out.println(stock); } }catch(Exception e) { e.printStackTrace(); } } } 출처 https://humble.tistory.com/23 https://sangwoo0727.github.io/java/JAVA-29_SAXParser/ 반응형
[Java] XML 파싱1. XML 파싱 JSON이 편리하고 많이 사용되는게 사실이지만, XML 또한 많이 사용되는 것도 사실입니다. 그렇기 때문에, 데이터를 XML로 만드는 것과 XML을 파싱해서 데이터를 이용하는 것 둘 다 할 줄 알아야합니다. XML 파싱이라는 작업이 워낙에 일반적이다보니 Java는 XML 파서를 내장하고 있습니다. 2. 내장 라이브러리를 사용한 XML 파싱 예제 아래와 같은 구조의 XML 파일이 있다고하겠습니다. Alsa 25 Bob 28 태그의 값을 가져오고 싶다면 어떻게 해야 할까요? 🤔 public class DemoXmlParser { public void getXmlData(File xmlFile) { // 1. 빌더 팩토리 생성. DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance(); // 2. 빌더 팩토리로부터 빌더 생성 DocumentBuilder builder = builderFactory.newDocumentBuilder(); // 3. 빌더를 통해 XML 문서를 파싱해서 Document 객체로 가져온다. Document document = builder.parse(xmlFile); // 문서 구조 안정화 ? document.getDocumentElement().normalize(); // XML 데이터 중 태그의 내용을 가져온다. NodeList personTagList = document.getElementByTagName(“person”); // 태그 리스트를 하나씩 돌면서 값들을 가져온다. for (int i = 0; i < personTagList.getLength(); ++i) { // 속성 값 가져오기. String name = personTagList.item(i).getAttributes().getNamedItem("sex").getNodeValue(); // 태그의 하위 노드들을 가져온다. ( 여기서 노드는 태그를 의미한다. ) NodeList childNodes = personTagList.item(i).getChildNodes(); for (int j = 0; j < childNodes.getLength(); ++j) { if ("name".equals(childNodes.item(j).getNodeName()) { // do somthing... } if ("age".equals(childNodes.item(j).getNodeName()) { // do somthing... } } } } } 위의 코드를 보면, 파싱할 XML 파일을 Document 객체에 담아옵니다. 이제 이 Document 객체를 가지고 파싱 작업을 진행하는데요, 위에선 Document#getElementByTagName 메서드를 이용해 태그를 리스트의 형태로 들고왔습니다. 가져온 태그 목록을 NodeList 객체에 담았는데 하나의 XML 태그가 하나의 Node 객체에 매핑되기 때문입니다. 자바 XML 처리 – DOM 파서(1) XML 읽기 XML은 플랫폼과 프로그램으로부터 독립적이며 개방된 표준으로 인간과 기계 모두 처리할 수 있는 마크업 언어입니다. ※ 여기서 잠깐! 마크업(markup) 언어: 태그 등을 이용하여 문서나 데이터의 구조를 명기하는 언어의 한 가지 XML을 처리할 때는 XML 파서를 사용합니다. XML 파서에는 몇 가지 종류가 있습니다. 각각의 처리 방식의 특징을 이해하고 용도에 맞는 최적의 처리 방법을 선택해야 합니다. 먼저 DOM(Document Object Model) 파서를 알아봅시다. DOM 파서란? DOM 파서는 XML을 파싱 하여 메모리 상에 XML 구조에 대응하는 객체의 트리를 유지합니다. 자바에서는 DOM 트리를 찾아 임의의 노드에 접근하는 것을 XPath로 검색합니다. 또한, DOM은 참조뿐만 아니라 XML에 내보내기도 지원하고 있으며, DOM 트리에 대한 변경 사항을 추가하여 XML로 출력할 수 있습니다. 트리로 구성되어 있기 때문에 구조를 파악하기 쉬운 방식이지만, 읽는 XML 크기가 클 때는 트리도 커지기 때문에 메모리를 대량으로 소비한다는 단점이 있습니다. DOM 파서로 XML 읽기 DOM 트리를 구성하는 각 노드에 대응하는 인터페이스는 org.w3c.dom.Node 인터페이스를 상속합니다. Node 인터페이스의 getNodeType() 메서드에서 해당 노드 종류를 판정할 수 있습니다. 노드 종류에는 대표적으로 요소(Element), 텍스트(Text)가 있습니다. 한 가지 더 중요한 인터페이스로 org.w3c.dom.NodeList 인터페이스가 있습니다. Node 인터페이스의 getChildNodes() 메서드로 자식 노드 목록을 NodeList 객체로 얻을 수 있습니다. 위의 XML 파일을 DOM을 사용하여 읽어봅시다. import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMParser { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException{ // XML 문서 파싱 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder documentBuilder = factory.newDocumentBuilder(); Document document = documentBuilder.parse(“sample.xml”); // root 구하기 Element root = document.getDocumentElement(); // root의 속성 System.out.println(“class name: ” + root.getAttribute(“name”)); NodeList childeren = root.getChildNodes(); // 자식 노드 목록 get for(int i = 0; i < childeren.getLength(); i++){ Node node = childeren.item(i); if(node.getNodeType() == Node.ELEMENT_NODE){ // 해당 노드의 종류 판정(Element일 때) Element ele = (Element)node; String nodeName = ele.getNodeName(); System.out.println("node name: " + nodeName); if(nodeName.equals("teacher")){ System.out.println("node attribute: " + ele.getAttribute("name")); } else if(nodeName.equals("student")){ // 이름이 student인 노드는 자식노드가 더 존재함 NodeList childeren2 = ele.getChildNodes(); for(int a = 0; a < childeren2.getLength(); a++){ Node node2 = childeren2.item(a); if(node2.getNodeType() == Node.ELEMENT_NODE){ Element ele2 = (Element)node2; String nodeName2 = ele2.getNodeName(); System.out.println("node name2: " + nodeName2); System.out.println("node attribute2: " + ele2.getAttribute("num")); } } } } } } } - 추가 내용 String xml = ~; InputSource is = new InputSource(new StringReader(xml)); documentBuilder = factory.newDocumentBuilder(); document = documentBuilder.parse(is); abc 일 때 ‘abc’ 읽어오기 Node node = childeren.item(a); if(node.getNodeType() == Node.ELEMENT_NODE){ Element ele = (Element)node; System.out.println(ele.getTextContent()); } 출처 : https://m.blog.naver.com/qbxlvnf11/221324667993 728×90 [Java] 자바를 이용한 XML 파싱(SAX parser 활용) On This Page SAX Parser 출처 이전 포스팅에서 자바에서 XML을 파싱하는 방법으로 SOX Parser와 DOM Parser가 있다는 것을 설명하였다. 이번 포스팅에서는 SAX Parser에 대해 구체적으로 코드를 통해 적어보려 한다. SAX 파서에 대해 다시 한 번 알아보자. SAX Parser Simple API for XML Parser의 약어로, 자바 API에서 제공한다. 기본적으로 SAX 파서는 문서를 순회하며 event가 발생하면서 순차적으로 파싱을 하게 된다. SAX는 XML 문서를 읽어들여서 어떤 태그를 만나면 그에 따라 이벤트를 생성한다. SAX에는 기본적으로 세가지 이벤트가 발생하고, 각각의 메소드는 아래와 같다. startElement() : 태그를 처음 만나면, 발생하는 이벤트 endElement() : 닫힌 태그를 만나면 발생하는 이벤트 characters() : 태그와 태그 사이의 text(내용)을 처리하기 위한 이벤트 예제 코드를 통해 알아보자. 30 홍길동 Male Java Developer 30 김철수 Male Designer 21 김영희 Female FrontEnd 28 김영심 Female MD 간단하게 작성한 xml 코드가 있다. valid하진 않다. 이 xml 파일을 SAX parser를 통해 파싱을 해보겠다. 먼저 xml을 파싱하여 저장할 Person 클래스를 간단히 setter와 getter를 통해 작성하겠다. 접근지시자는 무시하고 작성한다. public class Person { private int age ; private String name ; private String gender ; private String role ; public Person () { }; public int getAge () { return age ; } public void setAge ( int age ) { this . age = age ; } public String getName () { return name ; } public void setName ( String name ) { this . name = name ; } public String getGender () { return gender ; } public void setGender ( String gender ) { this . gender = gender ; } public String getRole () { return role ; } public void setRole ( String role ) { this . role = role ; } @Override public String toString () { return “이름:” + name + ” 나이:” + age + ” 성별:” + gender + ” 직책:” + role + ” ” ; } } SAX를 통해 파싱을 하기 위해서는 먼저 DefaultHandler를 상속받는 Handler 클래스를 작성해야 한다. import java.util.ArrayList ; import java.util.List ; import org.xml.sax.Attributes ; import org.xml.sax.helpers.DefaultHandler ; public class PeopleSaxHandler extends DefaultHandler { //파싱한 사람객체를 넣을 리스트 private List < Person > personList ; //파싱한 사람 객체 private Person person ; //character 메소드에서 저장할 문자열 변수 private String str ; public PeopleSaxHandler () { personList = new ArrayList <>(); } public void startElement ( String uri , String localName , String name , Attributes att ) { //시작 태그를 만났을 때 발생하는 이벤트 if ( name . equals ( “person” )) { person = new Person (); personList . add ( person ); } } public void endElement ( String uri , String localName , String name ) { //끝 태그를 만났을 때, if ( name . equals ( “age” )) { person . setAge ( Integer . parseInt ( str )); } else if ( name . equals ( “name” )) { person . setName ( str ); } else if ( name . equals ( “gender” )) { person . setGender ( str ); } else if ( name . equals ( “role” )) { person . setRole ( str ); } } public void characters ( char [] ch , int start , int length ) { //태그와 태그 사이의 내용을 처리 str = new String ( ch , start , length ); } public List < Person > getPersonList (){ return personList ; } public void setPersonList ( List < Person > personList ) { this . personList = personList ; } } 위에서 언급한 세가지 이벤트에 대해 이해하기 쉽게 간단한 코드로 작성해보았다. 이제 테스트를 위한 코드를 작성하겠다. package xml ; import java.io.File ; import java.util.List ; import javax.xml.parsers.SAXParser ; import javax.xml.parsers.SAXParserFactory ; public class PersonSaxTest { public static void main ( String [] args ) { File file = new File ( “./src/xml/people.xml” ); SAXParserFactory factory = SAXParserFactory . newInstance (); try { SAXParser parser = factory . newSAXParser (); PeopleSaxHandler handler = new PeopleSaxHandler (); parser . parse ( file , handler ); List < Person > list = handler . getPersonList (); for ( Person p: list ) { System . out . println ( p ); } } catch ( Exception e ) { e . printStackTrace (); } } } file 대신, api 키로 만들어진 uri 주소를 넣어도 가능하다. 출력을 통해 xml 파일을 원하는 대로 파싱하여, 출력한 결과를 확인 할 수 있다. 출처 https://jlblog.me https://jang8584.tistory.com https://pilgood.tistory.com
JAVA XML 파싱으로 데이터 가져오기
반응형 오늘은 자바 XML 파싱에 대해서 알아보려고 한다. 사실 요즘 XML은 잘 사용하지 않는 편이고 JSON을 많이 사용하지만 XML도 아직까지 많이 남아 있는 느낌이다. 우리 회사에도 새롭게 개발되는 내용은 JSON을 사용하지만 기존에 데이터 통신은 XML을 사용하고 있다. 이번 프로젝트 때 XML을 JSON으로 바꾸면 좋았지만 다른 쪽에서 그만큼 개발이 많이 들어가야 한다고 해서 XML로 진행을 하였다. XML은 JSON 처럼 쉽게 파싱을 해주는 라이브러리가 존재하진 않았다. 그래서 문서를 파싱하여 Node별로 나누어 사용하게 된다. EX) XML 데이터 예시 EX) 자바 XML 파싱 예시 public String fnGetAttribute(String sXmlData, String sNodeName, String sAttribute) throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder; Document doc; String rAttribute = “”; try { // XML 문서 파싱 InputSource is = new InputSource(new StringReader(sXmlData)); builder = factory.newDocumentBuilder(); doc = builder.parse(is); Element root = doc.getDocumentElement(); //Get Root Node NodeList childeren = root.getChildNodes(); // 자식 노드 목록 get for(int i = 0; i < childeren.getLength(); i++){ Node node = childeren.item(i); if(node.getNodeType() == Node.ELEMENT_NODE && sNodeName.equals(node.getNodeName())) { Element ele = (Element)node; rAttribute = ele.getAttribute(sAttribute); } } } catch (Exception e) { e.printStackTrace(); throw new Exception(); } return rAttribute; } 해당 예시는 XML 파일에서 내가 원하는 값을 가져오고 싶을 때 만든 함수이다. 변수 명 변수 설명 예시 Stirng sXmlData Xml Data 위 XML 예시 데이터 String sNodeName 데이터를 가져오고 싶은 노드명 Header,Detail String sAttribute 데이터를 가져오고 싶은노드의 Attribute TotalPrice, GoodsNm String totalPrice = fnGetAttribute(sXmlData, "Header", "TotalPrice"); sXmlData에 예시 데이터가 들어가 있다는 가정을 한다면 해당 함수를 이렇게 사용할 수 있다. 반응형 자바 xml 데이터, 속성 파싱(java xml parsing data, attribute) 안녕하세요. 오랜만에 자바관련 포스팅을 합니다. 나중에도 요긴하게 쓰일거같아 기본 코딩만 해두고 포스팅하려고 합니다. xml 데이터 파싱을 해보겠습니다. (java xml parsing data and attribute) 우선 테스트 xml 입니다. 홍길동 25 A B C 임꺽정 22 AA BB CC xml 구조는 테스트로 만든것이기 때문에 이해하기 쉬울 거라 생각됩니다. 제가 구현한 소스 입니다. import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class XmlExtraction { public void getXmlData(File xmlFile) throws Exception { //1.문서를 읽기위한 공장을 만들어야 한다. DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); //2.빌더 생성 DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); //3.생성된 빌더를 통해서 xml문서를 Document객체로 파싱해서 가져온다 Document doc = dBuilder.parse(xmlFile); doc.getDocumentElement().normalize();//문서 구조 안정화 Element root = doc.getDocumentElement(); NodeList n_list = root.getElementsByTagName(“person”); Element el = null; NodeList sub_n_list = null; //sub_n_list Element sub_el = null; //sub_el Node v_txt = null; String value=””; String[] tagList = {“name”, “age”, “job”}; for(int i=0; i 키워드에 대한 정보 자바 xml 파싱 다음은 Bing에서 자바 xml 파싱 주제에 대한 검색 결과입니다. 필요한 경우 더 읽을 수 있습니다. 이 기사는 인터넷의 다양한 출처에서 편집되었습니다. 이 기사가 유용했기를 바랍니다. 이 기사가 유용하다고 생각되면 공유하십시오. 매우 감사합니다! 사람들이 주제에 대해 자주 검색하는 키워드 [SWTT] xml문서의 구조와 Parsing 동영상 공유 카메라폰 동영상폰 무료 올리기 [SWTT] #xml문서의 #구조와 #Parsing YouTube에서 자바 xml 파싱 주제의 다른 동영상 보기 주제에 대한 기사를 시청해 주셔서 감사합니다 [SWTT] xml문서의 구조와 Parsing | 자바 xml 파싱, 이 기사가 유용하다고 생각되면 공유하십시오, 매우 감사합니다.
Java DOM Parser – Parse XML Document
Java DOM Parser – Parse XML Document
Advertisements
Steps to Using JDOM
Following are the steps used while parsing a document using JDOM Parser.
Import XML-related packages.
Create a SAXBuilder.
Create a Document from a file or stream
Extract the root element
Examine attributes
Examine sub-elements
Import XML-related packages
import org.w3c.dom.*; import javax.xml.parsers.*; import java.io.*;
Create a DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder();
Create a Document from a file or stream
StringBuilder xmlStringBuilder = new StringBuilder(); xmlStringBuilder.append(“
“); ByteArrayInputStream input = new ByteArrayInputStream( xmlStringBuilder.toString().getBytes(“UTF-8”)); Document doc = builder.parse(input); Extract the root element
Element root = document.getDocumentElement();
Examine attributes
//returns specific attribute getAttribute(“attributeName”); //returns a Map (table) of names/values getAttributes();
Examine sub-elements
//returns a list of subelements of specified name getElementsByTagName(“subelementName”); //returns a list of all child nodes getChildNodes();
Demo Example
Here is the input xml file that we need to parse −
dinkar kad dinkar 85 Vaneet Gupta vinni 95 jasvir singn jazz 90 DomParserDemo.java
package com.tutorialspoint.xml; import java.io.File; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.DocumentBuilder; import org.w3c.dom.Document; import org.w3c.dom.NodeList; import org.w3c.dom.Node; import org.w3c.dom.Element; public class DomParserDemo { public static void main(String[] args) { try { File inputFile = new File(“input.txt”); DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); Document doc = dBuilder.parse(inputFile); doc.getDocumentElement().normalize(); System.out.println(“Root element :” + doc.getDocumentElement().getNodeName()); NodeList nList = doc.getElementsByTagName(“student”); System.out.println(“—————————-“); for (int temp = 0; temp < nList.getLength(); temp++) { Node nNode = nList.item(temp); System.out.println(" Current Element :" + nNode.getNodeName()); if (nNode.getNodeType() == Node.ELEMENT_NODE) { Element eElement = (Element) nNode; System.out.println("Student roll no : " + eElement.getAttribute("rollno")); System.out.println("First Name : " + eElement .getElementsByTagName("firstname") .item(0) .getTextContent()); System.out.println("Last Name : " + eElement .getElementsByTagName("lastname") .item(0) .getTextContent()); System.out.println("Nick Name : " + eElement .getElementsByTagName("nickname") .item(0) .getTextContent()); System.out.println("Marks : " + eElement .getElementsByTagName("marks") .item(0) .getTextContent()); } } } catch (Exception e) { e.printStackTrace(); } } } This would produce the following result − Root element :class ---------------------------- Current Element :student Student roll no : 393 First Name : dinkar Last Name : kad Nick Name : dinkar Marks : 85 Current Element :student Student roll no : 493 First Name : Vaneet Last Name : Gupta Nick Name : vinni Marks : 95 Current Element :student Student roll no : 593 First Name : jasvir Last Name : singn Nick Name : jazz Marks : 90
자바 XML 처리 – DOM 파서(1) XML 읽기
XML은 플랫폼과 프로그램으로부터 독립적이며 개방된 표준으로 인간과 기계 모두 처리할 수 있는 마크업 언어입니다.
※ 여기서 잠깐!
마크업(markup) 언어: 태그 등을 이용하여 문서나 데이터의 구조를 명기하는 언어의 한 가지
XML을 처리할 때는 XML 파서를 사용합니다.
XML 파서에는 몇 가지 종류가 있습니다.
각각의 처리 방식의 특징을 이해하고 용도에 맞는 최적의 처리 방법을 선택해야 합니다.
먼저 DOM(Document Object Model) 파서를 알아봅시다.
DOM 파서란?
DOM 파서는 XML을 파싱 하여 메모리 상에 XML 구조에 대응하는 객체의 트리를 유지합니다.
자바에서는 DOM 트리를 찾아 임의의 노드에 접근하는 것을 XPath로 검색합니다.
또한, DOM은 참조뿐만 아니라 XML에 내보내기도 지원하고 있으며, DOM 트리에 대한 변경 사항을 추가하여 XML로 출력할 수 있습니다.
트리로 구성되어 있기 때문에 구조를 파악하기 쉬운 방식이지만, 읽는 XML 크기가 클 때는 트리도 커지기 때문에 메모리를 대량으로 소비한다는 단점이 있습니다.
DOM 파서로 XML 읽기
DOM 트리를 구성하는 각 노드에 대응하는 인터페이스는 org.w3c.dom.Node 인터페이스를 상속합니다.
Node 인터페이스의 getNodeType() 메서드에서 해당 노드 종류를 판정할 수 있습니다.
노드 종류에는 대표적으로 요소(Element), 텍스트(Text)가 있습니다.
한 가지 더 중요한 인터페이스로 org.w3c.dom.NodeList 인터페이스가 있습니다.
Node 인터페이스의 getChildNodes() 메서드로 자식 노드 목록을 NodeList 객체로 얻을 수 있습니다.
위의 XML 파일을 DOM을 사용하여 읽어봅시다.
import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DOMParser { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException{ // XML 문서 파싱 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder documentBuilder = factory.newDocumentBuilder(); Document document = documentBuilder.parse(“sample.xml”); // root 구하기 Element root = document.getDocumentElement(); // root의 속성 System.out.println(“class name: ” + root.getAttribute(“name”)); NodeList childeren = root.getChildNodes(); // 자식 노드 목록 get for(int i = 0; i < childeren.getLength(); i++){ Node node = childeren.item(i); if(node.getNodeType() == Node.ELEMENT_NODE){ // 해당 노드의 종류 판정(Element일 때) Element ele = (Element)node; String nodeName = ele.getNodeName(); System.out.println("node name: " + nodeName); if(nodeName.equals("teacher")){ System.out.println("node attribute: " + ele.getAttribute("name")); } else if(nodeName.equals("student")){ // 이름이 student인 노드는 자식노드가 더 존재함 NodeList childeren2 = ele.getChildNodes(); for(int a = 0; a < childeren2.getLength(); a++){ Node node2 = childeren2.item(a); if(node2.getNodeType() == Node.ELEMENT_NODE){ Element ele2 = (Element)node2; String nodeName2 = ele2.getNodeName(); System.out.println("node name2: " + nodeName2); System.out.println("node attribute2: " + ele2.getAttribute("num")); } } } } } } } - 추가 내용 String xml = ~; InputSource is = new InputSource(new StringReader(xml)); documentBuilder = factory.newDocumentBuilder(); document = documentBuilder.parse(is);
abc 일 때 ‘abc’ 읽어오기Node node = childeren.item(a); if(node.getNodeType() == Node.ELEMENT_NODE){ Element ele = (Element)node; System.out.println(ele.getTextContent()); }
출처 : https://m.blog.naver.com/qbxlvnf11/221324667993
728×90
[Java] 자바를 이용한 XML 파싱(SAX parser 활용)
On This Page SAX Parser
출처
이전 포스팅에서 자바에서 XML을 파싱하는 방법으로 SOX Parser와 DOM Parser가 있다는 것을 설명하였다.
이번 포스팅에서는 SAX Parser에 대해 구체적으로 코드를 통해 적어보려 한다.
SAX 파서에 대해 다시 한 번 알아보자.
SAX Parser
Simple API for XML Parser의 약어로, 자바 API에서 제공한다.
기본적으로 SAX 파서는 문서를 순회하며 event가 발생하면서 순차적으로 파싱을 하게 된다.
SAX는 XML 문서를 읽어들여서 어떤 태그를 만나면 그에 따라 이벤트를 생성한다.
SAX에는 기본적으로 세가지 이벤트가 발생하고, 각각의 메소드는 아래와 같다.
startElement() : 태그를 처음 만나면, 발생하는 이벤트
endElement() : 닫힌 태그를 만나면 발생하는 이벤트
characters() : 태그와 태그 사이의 text(내용)을 처리하기 위한 이벤트
예제 코드를 통해 알아보자.
30 홍길동 Male Java Developer 30 김철수 Male Designer 21 김영희 Female FrontEnd 28 김영심 Female MD 간단하게 작성한 xml 코드가 있다. valid하진 않다.
이 xml 파일을 SAX parser를 통해 파싱을 해보겠다.
먼저 xml을 파싱하여 저장할 Person 클래스를 간단히 setter와 getter를 통해 작성하겠다. 접근지시자는 무시하고 작성한다.
public class Person { private int age ; private String name ; private String gender ; private String role ; public Person () { }; public int getAge () { return age ; } public void setAge ( int age ) { this . age = age ; } public String getName () { return name ; } public void setName ( String name ) { this . name = name ; } public String getGender () { return gender ; } public void setGender ( String gender ) { this . gender = gender ; } public String getRole () { return role ; } public void setRole ( String role ) { this . role = role ; } @Override public String toString () { return “이름:” + name + ” 나이:” + age + ” 성별:” + gender + ” 직책:” + role + ”
” ; } }
SAX를 통해 파싱을 하기 위해서는 먼저 DefaultHandler를 상속받는 Handler 클래스를 작성해야 한다.
import java.util.ArrayList ; import java.util.List ; import org.xml.sax.Attributes ; import org.xml.sax.helpers.DefaultHandler ; public class PeopleSaxHandler extends DefaultHandler { //파싱한 사람객체를 넣을 리스트 private List < Person > personList ; //파싱한 사람 객체 private Person person ; //character 메소드에서 저장할 문자열 변수 private String str ; public PeopleSaxHandler () { personList = new ArrayList <>(); } public void startElement ( String uri , String localName , String name , Attributes att ) { //시작 태그를 만났을 때 발생하는 이벤트 if ( name . equals ( “person” )) { person = new Person (); personList . add ( person ); } } public void endElement ( String uri , String localName , String name ) { //끝 태그를 만났을 때, if ( name . equals ( “age” )) { person . setAge ( Integer . parseInt ( str )); } else if ( name . equals ( “name” )) { person . setName ( str ); } else if ( name . equals ( “gender” )) { person . setGender ( str ); } else if ( name . equals ( “role” )) { person . setRole ( str ); } } public void characters ( char [] ch , int start , int length ) { //태그와 태그 사이의 내용을 처리 str = new String ( ch , start , length ); } public List < Person > getPersonList (){ return personList ; } public void setPersonList ( List < Person > personList ) { this . personList = personList ; } }
위에서 언급한 세가지 이벤트에 대해 이해하기 쉽게 간단한 코드로 작성해보았다.
이제 테스트를 위한 코드를 작성하겠다.
package xml ; import java.io.File ; import java.util.List ; import javax.xml.parsers.SAXParser ; import javax.xml.parsers.SAXParserFactory ; public class PersonSaxTest { public static void main ( String [] args ) { File file = new File ( “./src/xml/people.xml” ); SAXParserFactory factory = SAXParserFactory . newInstance (); try { SAXParser parser = factory . newSAXParser (); PeopleSaxHandler handler = new PeopleSaxHandler (); parser . parse ( file , handler ); List < Person > list = handler . getPersonList (); for ( Person p: list ) { System . out . println ( p ); } } catch ( Exception e ) { e . printStackTrace (); } } }
file 대신, api 키로 만들어진 uri 주소를 넣어도 가능하다.
출력을 통해 xml 파일을 원하는 대로 파싱하여, 출력한 결과를 확인 할 수 있다.
출처
https://jlblog.me
https://jang8584.tistory.com
https://pilgood.tistory.com
키워드에 대한 정보 자바 xml 파싱
다음은 Bing에서 자바 xml 파싱 주제에 대한 검색 결과입니다. 필요한 경우 더 읽을 수 있습니다.
이 기사는 인터넷의 다양한 출처에서 편집되었습니다. 이 기사가 유용했기를 바랍니다. 이 기사가 유용하다고 생각되면 공유하십시오. 매우 감사합니다!
사람들이 주제에 대해 자주 검색하는 키워드 자바 온라인 교육 | Java DOM Parser를 사용하여 XML 구문 분석
- Java tutorial
- Java parser
- dom parser
- XML tutorial
- java xml
- online java training
- java course online
- java online training
- java training
- java courses
- free java tutorial
- java training online
- Java (UoA Technology)
- Java (Software)
자바 #온라인 #교육 #| #Java #DOM #Parser를 #사용하여 #XML #구문 #분석
YouTube에서 자바 xml 파싱 주제의 다른 동영상 보기
주제에 대한 기사를 시청해 주셔서 감사합니다 자바 온라인 교육 | Java DOM Parser를 사용하여 XML 구문 분석 | 자바 xml 파싱, 이 기사가 유용하다고 생각되면 공유하십시오, 매우 감사합니다.