당신은 주제를 찾고 있습니까 “시계열 데이터 전처리 – 인공지능 10-02/ 시계열데이터의 특징과 전처리 방법“? 다음 카테고리의 웹사이트 kk.taphoamini.com 에서 귀하의 모든 질문에 답변해 드립니다: https://kk.taphoamini.com/wiki. 바로 아래에서 답을 찾을 수 있습니다. 작성자 Dr. Bean의 코딩교실 이(가) 작성한 기사에는 조회수 265회 및 좋아요 1개 개의 좋아요가 있습니다.
Table of Contents
시계열 데이터 전처리 주제에 대한 동영상 보기
여기에서 이 주제에 대한 비디오를 시청하십시오. 주의 깊게 살펴보고 읽고 있는 내용에 대한 피드백을 제공하세요!
d여기에서 인공지능 10-02/ 시계열데이터의 특징과 전처리 방법 – 시계열 데이터 전처리 주제에 대한 세부정보를 참조하세요
#딥러닝 #with캐글
인공지능 10-02/ 시계열데이터의 특징과 전처리 방법
시계열 데이터 전처리 주제에 대한 자세한 내용은 여기를 참조하세요.
시계열 데이터 전처리(Denoising Method)
시계열 데이터 전처리(Denoising Method) … 을 지니게 되고 이를 전처리 없이 머신러닝 알고리즘에 학습할 경우 단순 후행 예측, 성능 저하, …
Source: today-1.tistory.com
Date Published: 4/5/2021
View: 4789
3. 데이터 전처리 — PseudoLab Tutorial Book
시계열 데이터를 지도학습 문제로 변환 하기 위해서는 예측 대상이 되는 타겟 변수와 예측할 때 사용하는 입력 변수 쌍으로 데이터를 가공해야 합니다. 또한 딥러닝 모델을 …
Source: pseudo-lab.github.io
Date Published: 12/16/2022
View: 4892
시계열 데이터에서 전처리하는 방법 – ok-lab
시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다.
Source: ok-lab.tistory.com
Date Published: 11/1/2022
View: 8995
[시계열분석] 시계열 데이터 전처리 실습(Python)(1)
[시계열분석] 시계열 데이터 전처리 실습(Python)(1) – 시간현실반영 및 Scaling. YSY^ 2021. 3. 8. 15:45. 320×100. 반응형. [시계열분석] 시계열 데이터 전처리 방향 …Source: ysyblog.tistory.com
Date Published: 8/14/2021
View: 3762
시계열 데이터 전처리 – velog
시간의 흐름에 따라 관측치가 변하는 시계열(Time Series) 데이터의 전처리.
Source: velog.io
Date Published: 10/25/2021
View: 1133
시계열 데이터 패턴 추출 (Feature Engineering) 1
에서 다운받을 수 있다. 데이터 전처리 과정. String to DateTime; Frequency 설정; 시계열 데이터 요소 추출 (Count_trend, Count_seasonal); rolling …
Source: dsbook.tistory.com
Date Published: 1/2/2021
View: 320
AI를 위한 시계열 데이터 전처리 Video – MATLAB
시계열 데이터를 활용한 추세 분석, 장비의 이상 감지 등과 같은 AI 애플리케이션으로의 적용이 증가하고 있습니다. 이러한 시계열 데이터를 AI에 잘 접목시키기 …
Source: www.mathworks.com
Date Published: 9/28/2021
View: 433
시계열 데이터 전처리 | 시계열 데이터 분석 기초 Part.1 #Python …
시계열 데이터에서 전처리하는 방법 – ok-lab. 시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 …
Source: you.xosotanphat.com
Date Published: 1/29/2021
View: 6007
4.8 시계열 자료 다루기 – 데이터 사이언스 스쿨
시계열 자료는 인덱스가 날짜 혹은 시간인 데이터를 말한다. 판다스에서 시계열 자료를 생성하려면 인덱스를 DatetimeIndex 자료형으로 만들어야 한다.
Source: datascienceschool.net
Date Published: 2/7/2022
View: 2302
Top 22 시계열 데이터 전처리 The 7 Detailed Answer
데이터 전처리 — PseudoLab Tutorial Book 시계열 데이터를 지도학습 문제로 변환 하기 위해서는 예측 대상이 되는 타겟 변수와 예측할 때 사용하는 입력 …
Source: toplist.giarevietnam.vn
Date Published: 8/7/2022
View: 2213
주제와 관련된 이미지 시계열 데이터 전처리
주제와 관련된 더 많은 사진을 참조하십시오 인공지능 10-02/ 시계열데이터의 특징과 전처리 방법. 댓글에서 더 많은 관련 이미지를 보거나 필요한 경우 더 많은 관련 기사를 볼 수 있습니다.
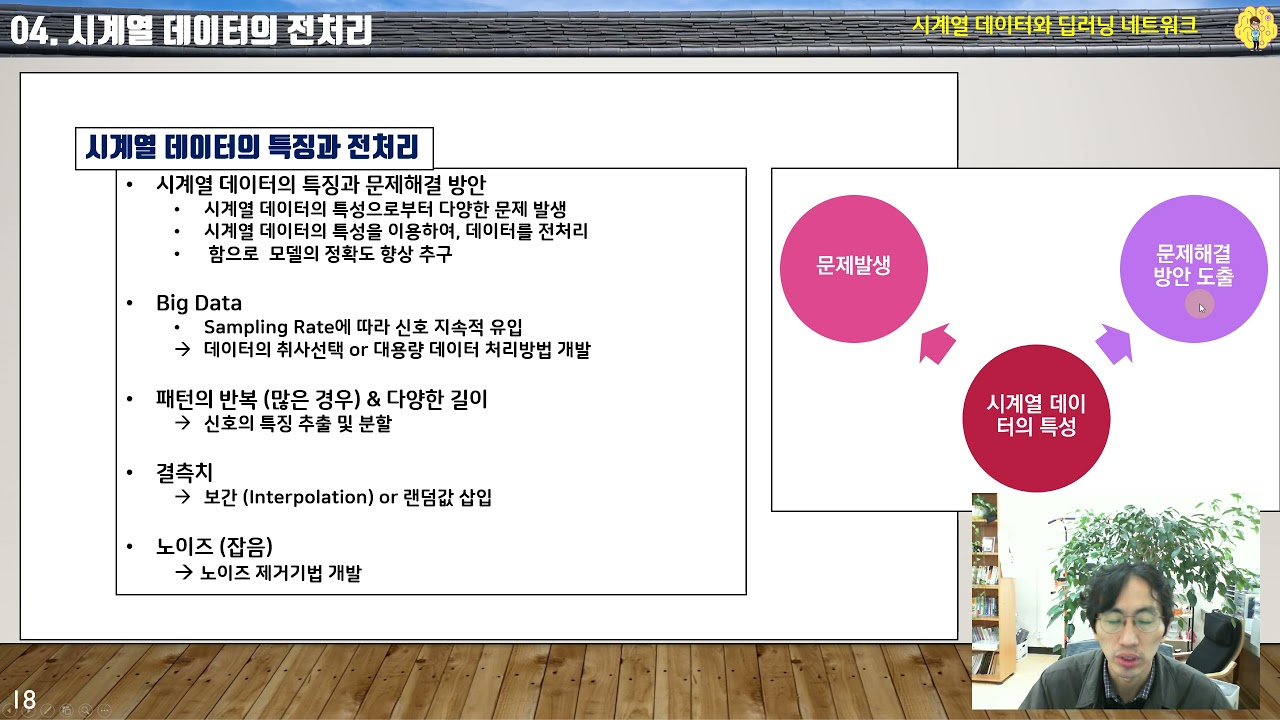
주제에 대한 기사 평가 시계열 데이터 전처리
- Author: Dr. Bean의 코딩교실
- Views: 조회수 265회
- Likes: 좋아요 1개
- Date Published: 2021. 11. 21.
- Video Url link: https://www.youtube.com/watch?v=LQGTOFHXGCQ
시계열 데이터 전처리(Denoising Method)
반응형
시계열 데이터를 분석하는 과정에서 시간 흐름에 따라 변동이 크거나 일정하지 않을 경우 비정상성(Non-Stationarity)을 지니게 되고 이를 전처리 없이 머신러닝 알고리즘에 학습할 경우 단순 후행 예측, 성능 저하, 잘못된 추론 등의 문제를 야기시킬 수 있습니다.
TIME SERIES FEATURES
시계열 데이터에는 일반적으로 시간 순차성(Time Step)과 지연 값(Lag)이라는 고유한 2가지 특성이 존재합니다. 두 특성 모두 시간 축을 바탕으로 발생하며 시계열 문제를 머신러닝 모델로 접근하고 해결하기 위해 유용한 특성입니다. 첫 번째, 시간 순차성(Time Step)은 시간축에서 직접 추출 가능하며 시작부터 끝가지 일정 시간 간격으로 측정된 년, 월, 일, 시간 특성이 대표적입니다. 이는 관측값이 주기적 성질을 지니고 있을 때 유용한 특성입니다. 두 번째, 지연 값(Lag)은 관측값에 시간 차이로 발생되며 현재 관측값들은 이전 관측값들로 표현됩니다. 이는 관측값이 자기 상관(AutoCorrelation) 또는 계열 상관성(SerialCorrelation)을 지니고 있을 때 유용한 특성입니다.
이번 포스트에서는 대표적으로 자기 상관(AutoCorrelation) 특성이 강한 금융 시계열 데이터에서 잡음(Noise)을 제거하고 추론에 도움이 되는 정보(Information)를 학습하기 위한 방법을 설명하겠습니다.
WHAT IS AUTOCORRELATION
자기 상관(AutoCorrelation)은 현재 관측값과 지연(Lag) 값들과의 관계에서 발생되는 대표적 요인 중 하나입니다. 해당 특성은 과거 관측된 값들이 미래 관측값에 영향을 지속적으로 미치기 때문에 관측값들의 관계를 우선적으로 파악하고 올바르게 처치해야 원하는 목적에 맞게 데이터를 활용할 수 있습니다. 관계성을 파악하기 위해 ACF/PACF 등을 사용하여 직관적으로 알아보거나 Durbin-Watson 검정을 통해 객관적으로 살펴볼 수 있습니다.
예제로 가져온 주식 종가 데이터를 ACF/PACF로 살펴보니 AR(1)의 특성을 보이고 있습니다. 금융 공학에서는 기하 브라운운동(GBM)을 가정하여 주식 종가 예측 모형을 진행하는데 AR(1)과 근본적으로는 유사하기 때문에 이를 바탕으로 모형을 변형하여 표현할 수 있습니다. 변형된 AR(1) 공식을 살펴보면 다음 주식 종가(t+1)는 현재 주식 종가(t) + 정보(t) + 잡음(t)으로 구성되어 있고 현재 주식 종가(t)를 좌변으로 옮기면 정보(t)와 잡음(t)을 살펴볼 수 있습니다.
시간에 따른 정보(Information)와 잡음(Noise)을 살펴보면 규칙성이 없고 분산이 일정하지 않습니다. 등분산성이 가정되지 않는다면 비정상 시계열이라 표현되며 이때 잡음(Noise)이 정보(Information)에 비해 상대적으로 더 큰 영향을 미치게 됩니다. 이로 인해 좋은 정보량을 잡음으로 인해 잃게 되고 다음 종가(t+1)는 현재 종가(t)와 잡음(t)으로 구성된 것처럼 설명되기에 예측 모델이 잔차를 최소화하기 위해 후행 예측을 야기하게 됩니다.
잡음(Noise)은 기존 신호의 간섭뿐만 아니라 여러 가지 의도치 않은 신호의 왜곡을 불러일으킬 수 있습니다. 그렇기 때문에 머신러닝 모델이 신호를 잘 이해하고 올바른 패턴을 학습시키기 위해 잡음 제거(Denoise)하는 데이터 전처리가 필요합니다.
TIME SERIES DENOISING
시계열 데이터에서 잡음 제거(Denoising) 방법으로 추세를 살펴볼 때 사용하는 이동평균선(Moving-Average)부터 시작하여 쌍방 필터(Bilateral Filter), 딥러닝을 활용한 잡음 제거 방식까지 예제 데이터를 가져와 코드와 함께 소개해드리겠습니다.
# 예제로 사용할 주식 데이터 가져오기 !pip install finance-datareader import pandas as pd import FinanceDataReader as fdr start_date = ‘20210101’ end_date = ‘20211231’ sample_code = ‘005930’ # 삼성전자 stock = fdr.DataReader(sample_code, start = start_date, end = end_date)
(1) Simple Moving Average
가장 먼저 소개해 드리는 방법은 단순 이동평균입니다. 단순 이동평균의 경우 주식투자 경험이 있으신 분이라면 한 번쯤은 접해보셨을 추세선입니다. 이는 구현 및 적용이 용이하나 적절한 파라미터 설정과 값이 우측으로 지연되는 특성이 있어 권하는 방법은 아닙니다.
def SMA(df, col, window=2): return df[col].rolling(window=window, min_periods=1).mean() stock[‘MA(5)’] = SMA(stock, ‘Close’, 5)
(2) Exponetial Moving Average
다음은 지수 이동평균입니다. 지수이동평균은 최근값에 가중치를 주며 이동평균을 계산합니다. 이때 평활 계수(EP = 2/(기간+1)를 사용하여 지수이동평균을 계산하게 됩니다. 지수이동평균 = (종가(t) x EP) + (지수 이동평균(t-1) x (1-EP))
def EMA(df, col, span=2): return df[col].ewm(span=span).mean() stock[‘EMA(5)’] = EMA(stock, ‘Close’, 5)
(3) Fourier Transform
다음은 푸리에 변환(Fourier Transform)입니다. 푸리에 변환은 이전 포스팅에서 설명드린 내용이며 푸리에는 어떤 복잡한 파동이라도 진동수와 진폭이 다른 간단한 파동들의 합으로 나타낼 수 있다는 것을 증명했습니다. 이를 잡음 제거에 활용하면 시간 차원에서 발생한 주식 종가 가격을 주파수 차원으로 변환하여 특정 상위 파동들의 합(예시에서는 상위 30개)을 계산하고 다시 시간 차원으로 변환합니다. 이를 통해 잡음을 제거하여 올바른 신호를 포착할 수 있습니다.
def FFT(df, col, topn=2): fft = np.fft.fft(df[col]) fft[topn:-topn] = 0 ifft = np.fft.ifft(fft) return ifft stock[‘FFT(30)’] = FFT(stock, ‘Close’, 30)
복잡한 파동을 단순한 파동들의 합으로 표현하고 다시 시간차원으로 변환시키는 과정에서 시간축의 정보가 손실되기 때문에 우리는 해당 신호가 정확히 어느 시점에서 존재했는지 알 수 없습니다. 복잡한 신호일 수록 이런 단점이 더 부각되는데 이를 방지하고자 특정 시간 구간별로 푸리에 변환을 진행하는 STFT(Short Time Fourier Transform)이 소개되었습니다. 하지만 STFT 또한 특정 시간대(=window size)를 설정해야 하는데 이를 길게 잡으면 주파수의 해상도는 상승하지만 시간에 대한 해상도는 하락하고 이를 짧게 잡으면 주파수 해상도가 감소하고 시간에 대한 해상도는 상승합니다. 이와 같이 시간과 주파수 해상도에 대해 Trade-off 관계를 가지고 있어 사용에 유의하셔야 합니다. 본 포스팅에서는 STFT는 따로 코드 구현으로 활용하지 않겠습니다.(FFT 코드 활용하시면 쉽게 구현 가능합니다.)
(4) Wavelet Transform
다음은 웨이블릿 변환(Wavelet Transform)입니다. 웨이블릿 변환은 푸리에 변환의 단점을 해소하고자 개발되었고 고주파 성분 신호에 대해서는 주파수 해상도를 높이고 시간 해상도를 낮추는 한편 저주파 성분 신호에 대해서는 주파수 해상도를 낮추고 시간 해상도를 높이는 웨이블릿 함수를 사용합니다. 이렇듯 웨이블릿 변환은 시간의 확장과 축소하는 Scaling과 시간 축으로 이동되는 Shifting이 핵심입니다. 또한 동일한 자료를 분석하더라도 모 웨이블릿의 선택에 따라 결과가 달라지기 때문에 데이터 특성에 맞는 모 웨이블릿을 잘 선택해야하 하며 이산 웨이블릿 변환을 위해 Haar, Daubechies 등을 많이 사용합니다. 본 예제에서는 Daubechies를 사용하여 보여드리겠습니다.
def WT(df, col, wavelet=’db5′, thresh=0.63): signal = df[col].values thresh = thresh*np.nanmax(signal) coeff = pywt.wavedec(signal, wavelet, mode=”per” ) coeff[1:] = (pywt.threshold(i, value=thresh, mode=”soft” ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode=”per” ) return reconstructed_signal
(5) AutoEncoder
다음은 AutoEncoder입니다. 이전까지 설명드렸던 잡음 제거 방법들은 데이터 특성에 따라 분석가가 파라미터를 하나하나 설정해야 했습니다. 이런 파라미터를 결정하는데 많은 시간과 비용이 소비되기 때문에 종단 간(end-to-end) 딥러닝 모델로 잡음을 제거할 수 있는 응용모델(AutoEncoder,.. etc)을 예측 모델과 연결시켜 학습을 진행한다면 학습 비용을 감소시키면서 효과적으로 성능을 향상할 수 있습니다.
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch.utils.data as data_utils class TimeDistributed(nn.Module): def __init__(self, module): super(TimeDistributed, self).__init__() self.module = module def forward(self, x): if len(x.size()) <= 2: return self.module(x) x_reshape = x.contiguous().view(-1, x.size(-1)) y = self.module(x_reshape) if len(x.size()) == 3: y = y.contiguous().view(x.size(0), -1, y.size(-1)) return y class Autoencoder(nn.Module): def __init__(self): super(Autoencoder, self).__init__() self.encoder = nn.LSTM( input_size = 1, hidden_size = 16, dropout = 0.25, num_layers = 2, bias = True, batch_first = True, bidirectional = True, ) self.decoder = nn.LSTM( input_size = 32, hidden_size = 16, dropout = 0.25, num_layers = 2, bias = True, batch_first = True, bidirectional = True, ) self.fc = TimeDistributed(nn.Linear(32, 1)) def forward(self, x): h0, (h_n, c_n) = self.encoder(x) h0, (h_n, c_n) = self.decoder(h0[:,-1:,:].repeat(1,5,1)) out = self.fc(h0) return out 해당 방법들을 통해 재 생성된 데이터들의 정보와 잡음이 어떻게 분포되어 있는지 시각화 자료로 살펴보면, 단순 이동평균(MA)과 지수 이동평균(EMA)은 기존 데이터에 비해 스무딩 된 표현을 얻었습니다. 하지만 여전히 큰 분산을 보이고 있어 이를 활용 시 성능 향상에 도움이 될지 알 수 없습니다. 다음으로 푸리에 변환(FFT)을 살펴보면 기존 방법들에 비해 더 부드러운 표현을 가지게 되었고 많은 잡음이 제거된 것으로 보입니다. 웨이블릿 변환(WT)은 푸리에 변환보다 더 부드러운 파동의 형태를 지니게 되어 기존 잡음과 더불어 정보까지 같이 손실된 것처럼 보입니다. 이는 모 웨이블릿을 어떤 걸 사용하느냐에 따라 큰 차이가 발생할 수 있으므로 여러 실험을 통해 알맞은 함수를 찾아야 잡음 제거 효과를 얻을 수 있습니다. 마지막으로 오토 인코더(AE)의 경우 기존 데이터와 푸리에 변환 중간쯤의 표현력을 지닌 것으로 보입니다. 잡음 제거가 잘 되었는지 확인하는데 편차의 분포를 보는 것보다 예측 모델로 실험 결과를 보는 게 가장 정확하고 평가할 수 있습니다. 비교 결과 푸리에 변환(FFT)이 가장 좋은 성능을 지니고 있었고 그다음으로는 오토 인코더(AE) 모델이 잡음 제거로 인해 좋은 성능을 보이고 있습니다. 그에 반해 이동평균(MA, EMA) 방법들은 과거의 결과 자료로써 데이터를 재 구성하는 방법이기 때문에 후행 예측이 여전히 존재하고 있는 것을 눈으로 확인할 수 있었으며 검증 데이터의 학습이 제대로 진행되지 않는 것을 볼 수 있습니다. 웨이블릿 변환(WT)의 경우 후행 예측 문제를 해소할 수 있으나 변환 작업에서 신호의 잡음과 정보를 같이 손실되어 정확도를 잃게됐습니다. 하지만 예측 결과를 살펴보면 추세를 판단하기에 좋은 방법이라고 생각되어집니다. RAW MA EMA(5) FFR(30) WT(db5) WT(db7) WT(db9) AE RMSE 1,349(3) 1,610 1,616 921(1) 1,426 1,778 1,539 1,095(2) MAE 930(3) 1,264 1,241 703(1) 1,225 1,405 1,127 775(2) MAPE 1.23(3) 1.67 1.64 0.93(1) 1.61 1.85 1.48 1.02(2) 금융 데이터는 자기 자신에 대해 영향을 미치는 자기 상관 특성이 강한 시계열 데이터입니다. 그렇기 때문에 이 데이터를 그대로 사용한다면 모델은 과거 데이터 속에 무시해야하는 무작위적 잡음을 분류해내지 못하고 실존하는 패턴과의 관계를 학습하지 못해 외삽(Extrapolate)해야할 진짜 패턴을 출력하지 못할것입니다. 그래서 우리는 모델에 데이터를 밀어줄 때 위와 같은 잡음 제거 방식을 사용해 올바른 정보만을 학습에 사용해야 합니다. LESSONS LEARNED 이번 포스트에서는 잡음 제거(Denoising) 방식으로 데이터에서 쓸모있는 정보만 추출해 사용하여 기존 예측 모델에서 발생했던 후행 예측, 성능 저하, 잘못된 추론 등의 문제를 해결했습니다. 빅데이터 분석 업무를 수행하다보면 다양하고 대량의 데이터들을 빈번히 접하게 됩니다. 그리고 항상 이 데이터를 전달해주시는 분들은 데이터의 양이 충분하니 데이터에서 새로운 모멘텀을 얻길 기대하지만 이를 효과적으로 활용하는 방안들에 대해 고민해야할 일이 많습니다. 이번 포스트를 통해 같은 고민이 있으신 분들에게 도움이 됐으면 좋겠습니다. 반응형
3. 데이터 전처리 — PseudoLab Tutorial Book
Cloning into ‘Tutorial-Book-Utils’… remote: Enumerating objects: 24, done. remote: Counting objects: 100% (24/24), done. remote: Compressing objects: 100% (20/20), done. remote: Total 24 (delta 6), reused 14 (delta 3), pack-reused 0 Unpacking objects: 100% (24/24), done. COVIDTimeSeries.zip is done!
시계열 데이터에서 전처리하는 방법
728×90
반응형
Contents
시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다. 결측치와 노이즈는 예측 성능을 떨어뜨리는 녀석들 중 하나이기에 사전에 전처리 과정을 수행하여 처리한 후 작업을 수행하는 것이 옳다.
결측치 (Missing Values)
결측치는 말 그대로 값이 존재하지 않는 값을 의미한다. 예를 들어, 식당의 매출을 예측하는 경우 식당의 휴무일에는 매출이 존재하지 않을 것이다. 이와 같은 경우 이를 제거하고 예측하는 형태로 진행할 수 있을 것이다. 실제 데이터를 다룰 때 휴무일과 같은 경우로 데이터가 없을 수도 있고, 단순히 누락되었을 수도 있다.
일반적인 데이터의 구성에서는 큰 문제가 되지 않는다면 결측치를 제거하면 된다. 그러나, 시계열 데이터에서 결측치를 제거하게 되는 경우 그 시점의 평균과 분산의 왜곡을 가져오게 되고 이는 분석 결과에 치명적인 영향을 미칠 수 있다. 휴무일과 같은 데이터는 제거하면 되지만, 누락된 값인 경우 대체함으로써 평균과 분산에 왜곡을 가져오기 때문이다.
그러나 현실에서 접하는 대부분의 데이터는 항상 결측치가 발생한다. 특히 시계열은 시간의 흐름에 따라 그 시기에 데이터를 직접 수집하는 것이기 때문에 그 시기에 네트워크 이슈 혹은 센서 에러 등의 이유로 수집이 불가하면 결측치가 발생하게 되는 것이다.
시계열 데이터가 아닌 경우에는 일반적으로 평균이나 분산으로 대체하거나 결측치를 제거하면 그만이다. 그러나 시계열 데이터는 그렇게 처리할 경우 문제가 발생한다. 그렇다면 시계열 데이터에서의 결측치는 어떻게 처리할 수 있을까? 시계열 데이터는 시간의 흐름에 따라 데이터의 평균과 분산이 변하기에 이러한 특징을 잘 반영하는 방법론을 활용해야 성공적으로 결측치를 대체할 수 있다. 대체하는 방법은 다음과 같다.
Last observation carried Forward (LOCF): 직전에 관측된 값으로 결측치를 대체
직전에 관측된 값으로 결측치를 대체 Next observation carried backwrd (NOCB): 직후에 관측된 값으로 결측치를 대체
직후에 관측된 값으로 결측치를 대체 Moving Average / Median: 직전 N의 time window의 평균치/중앙값으로 결측치를 대체
그러나 결측치 전후의 패턴이 변화하는 구간인 경우에는 이와 같은 방식으로 처리할 경우 문제가 발생한다. 예를 들어, 주가를 예측하는 경우 상승 구간이거나 하락 구간에 결측치가 존재할 때는 이전 값의 평균으로 대체하게 되면 실제 값과 차이가 발생하게 된다. 이런 경우에는 선형 보간법(Linear interpolation)을 통해 해당 값을 찾을 수 있다.
선형 보간법(Linear interpolation)
선형 보간법은 통계적으로 이미 구해진 데이터들로부터 t시점과 t+1시점 사이의 값을 유추하는 형태를 의미힌다. 예를 들어 끝점 $(x_0, y_0)$와 $(x_1, y_1)$가 주어졌을 때, 그 사이에 위치한 $(x,y)$의 값을 추정하기 위해 다음과 같은 수식을 세울 수 있다.
\[ \frac{y-y_0}{x-x_0} = \frac{y_1 – y_0}{x_1 – x_0} \]
\[ y= y_0 + (y_1 – y_0) \cdot \frac{x-x_0}{x_1 – x_0} \]
위 경우에는 선형 보간법에 대해서만 다루었으나, 선형 보간법 외에도 비선형, 스플라인 보간법 등 다양한 보간법이 존재한다. 필요에 따라 다양한 형태로 사잇값을 보간할 수 있다. 비선형 보간법은 선형 함수가 아닌 비선형 함수를 근사 함수로 사용하는 것을 의미하고, 스플라인(Spline) 보간법은 전체 구간을 근사하는 것이 아닌, 소구간으로 분할하여 보간하는 방법을 의미한다.
좌: Linear interpolation, 우: Linear Polinomial
만약 누락된 값이 너무 많은 경우에는 위와 같은 방법으로 처리를 할 수 없다. 이때는 모델링을 통해 해당 부분을 예측하는 형태로 진행하여야 한다. 일반적인 데이터라면 기존에 수집된 데이터로 결측치를 잘 설명할 수 있으나, 시계열 데이터는 시간에 따라 변화하기에 이를 모델링하는 것은 어렵다. 그러나 최근에는 GAN에 기반한 시계열 생성 알고리즘으로 이 부분을 채우고자 하는 연구가 많이 진행되고 있다.
노이즈(Noise)
노이즈는 잡음을 의미하며, 의도하지 않은 데이터의 왜곡을 불러오는 모든 것들을 칭한다. 예를 들어, 음성 처리의 경우 주변의 소음으로 인해 음성 인식이 제대로 되지 않는다면 이때 소음을 노이즈로 판단한다. 시계열 데이터에서는 원래 분포를 왜곡하는 모든 요인을 칭한다.
최근 주식 시장에서는 코로나 사태로 인해 주가가 엄청나게 하락을 하게 되었다. 이 때 해당 부분을 노이즈로 볼 것인지, 아닌지를 판단함에 따라 제거할수도, 제거하지 않을수도 있다. 시계열 데이터에서 노이즈를 제거하는 방법을 Denosing이라고 한다.
가장 간단한 Denosing 방법으로는 Moving Average가 있다. Moving Average는 평균값으로 관측치를 대체하는 방식이며, 이를 통해 이상하게 튀는 값을 평할화(Smoothing)할 수 있다. 노이즈가 정말 많은 환경에서는 노이즈 자체가 평균이 되어버리는 경우가 있으나, 노이즈가 간혹 발생하는 경우에는 매우 효과적이다. 그렇다면 노이즈가 많은 환경에는 어떻게 처리를 해야할까?
노이즈가 많은 환경에서는 노이즈를 Smoothing 혹은 Filtering 하는 법이 있다. 현재 시계열에 발생하는 노이즈가 어떤 특정한 분포를 따른다고 가정하고 해당 분포의 값을 시계열에서 제거하는 형태로 진행한다.
\[ x_{n+1} + \xi = Ax_{n}\]
여기서 $\xi$가 어떤 특정한 분포를 따른다고 가정하고, 이를 근사한 값을 제거함으로써 원래 값을 복원할 수 있다. 따라서, $Ax_n$를 구한다음 $\xi$를 빼서 원래 시계열 구조를 찾는 것이다. 특정한 분포는 일반적으로 가우시안(Gaussian) 분포를 많이 사용한다.
필터링(Filtering)
노이즈를 제거하는 대표적인 필터링 방법은 가우시안 필터링(Gaussian Filtering), 쌍방 필터(Bilateral Filter), 칼만 필터(Kalman Filter)가 있다. 가우시안 필터링은 노이즈가 정규분포를 따른다고 가정하는 것을 의미하고, 쌍방 필터는 변곡점이 큰 지점을 뭉개버리는 특징을 갖는 가우시안 필터링의 단점을 보완해 데이터의 원 분포에 따라 발생하는 엣지(Edge)들을 더 잘 보존하는 방법이다.
가우시안 필터링(Gaussian Filtering)
가우시안 필터링은 시계열 데이터 뿐만 아니라 이미지 처리에서도 많이 사용하는 Filter 중 하나이며, 수식은 다음과 같다.
\[ G(x,y) = \frac{1}{2 \pi \sigma^2} \exp(-\frac{x^2 + y^2}{2 \sigma^2}) \]
위 수식을 살펴보면 가우시안 필터에서 결정해야할 파라미터는 $\sigma$이다. 일반적으로 $1\sigma$는 68%, $2\sigma$는 95%, $3\sigma$는 99.7%를 설명한다고 알려져있기 때문에 $3\sigma$까지 고려할 때 정확도가 가장 높다고 한다.
경제학에서는 기본적으로 세상의 모든 현상을 가우시안 분포로 설명한다. 그러나 이러한 분포는 주식과 같은 경제 분야에서는 전혀 들어맞지 않는 상황이 발생할 수 있다. 일반적으로 주식 시장에서는 극단적인 경우가 많이 발생하기에 이러한 경우를 팻 테일(Fat Tail)이라 부른다. 이는 정규분포의 양 끝 모양이 더 뚱뚱한 것을 의미한다.
쌍방 필터(Bilateral Filter)
가우시안 필터링은 노이즈를 제거하는데 있어 효과적이지만, 경계성이 뭉개지는 현상이 있다. 이러한 문제점을 보완한 필터링이 바로 쌍방 필터링이며, 수식은 다음과 같다.
\[ \text{BF}[I]_p = \frac{1}{W_p} \sum_{q\in S} G_{\sigma_s} (||p-q||) \cdot G_{\sigma_r} (||I_p – I_q||) I_q \]
칼만 필터(Kalmal Filter)
칼만 필터는 잡음이 포함된 과거 측정값에서 현재 상태의 결합분포를 추정하는 알고리즘이다. 어떠한 정보가 있을 때 해당 데이터는 mixture 모델임(GMM과 같이)을 가정한다. 즉, 다른 분포들의 결합이라는 것을 가정한다. 일반화된 분포를 가정하는 것이 아닌 데이터의 특정에 맞는 분포를 모델링할 수 있어 상당히 많이 사용되며 특히 이미지 트래킹 분야에서 많이 사용되는 필터링 중 하나이다. 수식은 다음과 같다.
\[ \mu_{\text{new}} = \frac{\mu_2 \sigma^2_1 + \mu_1 \sigma^2_2}{\sigma^2_1 + \sigma^2_2} \]
\[ \sigma^2_{\text{new}} = \frac{\sigma^2_1 \sigma^2_2}{\sigma^2_1 + \sigma^2_2} \]
728×90
[시계열분석] 시계열 데이터 전처리 실습(Python)(1)
728×90
반응형
[시계열분석] 시계열 데이터 전처리 방향 – 시간현실 반영, Scaling, 다중공선성 처리 : ysyblog.tistory.com/217해당 포스팅은 위 포스팅에 이어 진행되는 실습입니다.
데이터 코딩은 아래 포스팅에 이어 진행됩니다.
[시계열분석] 시계열 변수 추출 실습(Python)(1) – 시계열 분해 (bike-sharing-demand dataset) :ysyblog.tistory.com/209 [시계열분석] 시계열 변수 추출 실습(Python)(2) – 이동평균/지연값/증감폭/그룹화 (bike-sharing-demand dataset) :ysyblog.tistory.com/210 [시계열분석] 시계열 변수 추출 실습(Python)(3) – 종속변수들과 독립변수들과의 관계를 파악하기 위한 시각화 (bike-sharing-demand dataset) :ysyblog.tistory.com/211 [시계열분석] 시계열 변수 추출 실습(Python)(4) – 시계열 데이터 준비(train/test set 분리) (bike-sharing-demand dataset) :ysyblog.tistory.com/212 [시계열분석] 기본 모델링 실습(Python) – 모델링 및 분석 성능 평가(bike-sharing-demand dataset) : ysyblog.tistory.com/215시간현실반영
Trend 처리
Test 기간의 FE데이터를 알 수 있을까?
1) 과거 패턴이 반복될 것이다
2) 하나씩 예측하며 업데이트
raw_fe[‘count_trend’].plot() #1년마다 늘어났다가 줄어드는 패턴을 보임, 이를 활용해서 예측
len(raw_fe.loc[‘2012-01-01′:’2012-12-31’, ‘count_trend’]) #8784 len(raw_fe.loc[‘2011-01-01′:’2011-12-31’, ‘count_trend’]) #8760 raw_fe.loc[‘2011-02-29’, ‘count_trend’] #2/29일 데이터가 없음(윤달)
# 2012년 데이터에 2011년데이터를 넣음 # date duplicattion by rules raw_fe.loc[‘2012-01-01′:’2012-02-28’, ‘count_trend’] = raw_fe.loc[‘2011-01-01′:’2011-02-28’, ‘count_trend’].values raw_fe.loc[‘2012-03-01′:’2012-12-31’, ‘count_trend’] = raw_fe.loc[‘2011-03-01′:’2011-12-31’, ‘count_trend’].values #2012-02-29 데이터 만들기 step = (raw_fe.loc[‘2011-03-01 00:00:00’, ‘count_trend’] – raw_fe.loc[‘2011-02-28 23:00:00’, ‘count_trend’])/25 #일정한 스텝을 만든다음 step_value = np.arange(raw_fe.loc[‘2011-02-28 23:00:00’, ‘count_trend’]+step, #더함 raw_fe.loc[‘2011-03-01 00:00:00’, ‘count_trend’], step) step_value = step_value[:24] raw_fe.loc[‘2012-02-29’, ‘count_trend’] = step_value
# result of duplication raw_fe[‘count_trend’].plot() # 2011년과 2012년이 같아짐
# result of duplication raw_fe[‘count_diff’].plot()
지연값 처리
train에서 지연된 값은 test로 들어가면 안된다.(미래시점을 안다고 하고 반영한꼴이기 때문)
따라서 train_lag의 끝값들을(test셋의 영역에 들어간 값들)을 test의 값들로 채워야함
# calculation of lag data from Y 따라서 test셋을 따로 만든다. X_test_fe[‘count_lag1’] = Y_test_fe.shift(1).values X_test_fe[‘count_lag1′].fillna(method=’bfill’, inplace=True) X_test_fe[‘count_lag2’] = Y_test_fe.shift(2).values X_test_fe[‘count_lag2′].fillna(method=’bfill’, inplace=True) X_train_fe[‘count_lag2’].plot()
코드요약
### Functionalize ### duplicate previous year values to next one def feature_engineering_year_duplicated(raw, target): raw_fe = raw.copy() for col in target: raw_fe.loc[‘2012-01-01′:’2012-02-28’, col] = raw.loc[‘2011-01-01′:’2011-02-28’, col].values raw_fe.loc[‘2012-03-01′:’2012-12-31’, col] = raw.loc[‘2011-03-01′:’2011-12-31’, col].values step = (raw.loc[‘2011-03-01 00:00:00’, col] – raw.loc[‘2011-02-28 23:00:00’, col])/25 step_value = np.arange(raw.loc[‘2011-02-28 23:00:00’, col]+step, raw.loc[‘2011-03-01 00:00:00’, col], step) step_value = step_value[:24] raw_fe.loc[‘2012-02-29’, col] = step_value return raw_fe # target = [‘count_trend’, ‘count_seasonal’, ‘count_Day’, ‘count_Week’, ‘count_diff’] # raw_fe = feature_engineering_year_duplicated(raw_fe, target) ### modify lagged values of X_test def feature_engineering_lag_modified(Y_test, X_test, target): X_test_lm = X_test.copy() for col in target: X_test_lm[col] = Y_test.shift(1).values X_test_lm[col].fillna(method=’bfill’, inplace=True) X_test_lm[col] = Y_test.shift(2).values X_test_lm[col].fillna(method=’bfill’, inplace=True) return X_test_lm
결과분석
raw_all = pd.read_csv(location) # Feature Engineering raw_rd = non_feature_engineering(raw_all) # Data Split # Confirm of input and output Y_colname = [‘count’] X_remove = [‘datetime’, ‘DateTime’, ‘temp_group’, ‘casual’, ‘registered’] X_colname = [x for x in raw_rd.columns if x not in Y_colname+X_remove] X_train_rd, X_test_rd, Y_train_rd, Y_test_rd = datasplit_ts(raw_rd, Y_colname, X_colname, ‘2012-07-01’) # Applying Base Model fit_reg1_rd = sm.OLS(Y_train_rd, X_train_rd).fit() display(fit_reg1_rd.summary()) pred_tr_reg1_rd = fit_reg1_rd.predict(X_train_rd).values pred_te_reg1_rd = fit_reg1_rd.predict(X_test_rd).values # Evaluation Score_reg1_rd, Resid_tr_reg1_rd, Resid_te_reg1_rd = evaluation_trte(Y_train_rd, pred_tr_reg1_rd, Y_test_rd, pred_te_reg1_rd, graph_on=True) display(Score_reg1_rd) # Error Analysis error_analysis(Resid_tr_reg1_rd, [‘Error’], X_train_rd, graph_on=True)
처음 모델링했던 것보다 결정계수는 소폭 줄었지만, 변수들의 p-value도 많이 유의해졌고, 에러율도 많이 낮아졌다.
Scaling
scaler = preprocessing.MinMaxScaler() scaler_fit = scaler.fit(X_train_feR) X_train_feRS = pd.DataFrame(scaler_fit.transform(X_train_feR), index=X_train_feR.index, columns=X_train_feR.columns) X_test_feRS = pd.DataFrame(scaler_fit.transform(X_test_feR), index=X_test_feR.index, columns=X_test_feR.columns) X_test_feRS.describe().T
코드요약
### Functionalize ### scaling of X_train and X_test by X_train_scaler def feature_engineering_scaling(scaler, X_train, X_test): # preprocessing.MinMaxScaler() # preprocessing.StandardScaler() # preprocessing.RobustScaler() # preprocessing.Normalizer() scaler = scaler scaler_fit = scaler.fit(X_train) X_train_scaling = pd.DataFrame(scaler_fit.transform(X_train), index=X_train.index, columns=X_train.columns) X_test_scaling = pd.DataFrame(scaler_fit.transform(X_test), index=X_test.index, columns=X_test.columns) return X_train_scaling, X_test_scaling
결과분석
raw_all = pd.read_csv(location) # Feature Engineering raw_fe = feature_engineering(raw_all) ### Reality ### target = [‘count_trend’, ‘count_seasonal’, ‘count_Day’, ‘count_Week’, ‘count_diff’] raw_feR = feature_engineering_year_duplicated(raw_fe, target) ############### # Data Split # Confirm of input and output Y_colname = [‘count’] X_remove = [‘datetime’, ‘DateTime’, ‘temp_group’, ‘casual’, ‘registered’] X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove] X_train_feR, X_test_feR, Y_train_feR, Y_test_feR = datasplit_ts(raw_feR, Y_colname, X_colname, ‘2012-07-01’) ### Reality ### target = [‘count_lag1’, ‘count_lag2’] X_test_feR = feature_engineering_lag_modified(Y_test_feR, X_test_feR, target) ############### ### Scaling ### X_train_feRS, X_test_feRS = feature_engineering_scaling(preprocessing.Normalizer(), X_train_feR, X_test_feR) ############### # Applying Base Model fit_reg1_feRS = sm.OLS(Y_train_feR, X_train_feRS).fit() display(fit_reg1_feRS.summary()) pred_tr_reg1_feRS = fit_reg1_feRS.predict(X_train_feRS).values pred_te_reg1_feRS = fit_reg1_feRS.predict(X_test_feRS).values # Evaluation Score_reg1_feRS, Resid_tr_reg1_feRS, Resid_te_reg1_feRS = evaluation_trte(Y_train_feR, pred_tr_reg1_feRS, Y_test_feR, pred_te_reg1_feRS, graph_on=True) display(Score_reg1_feRS) # Error Analysis error_analysis(Resid_tr_reg1_feRS, [‘Error’], X_train_feRS, graph_on=True)
처음 모델링했던 것보다 결정계수는 소폭 줄었지만, 변수들의 p-value도 많이 유의해졌고, 에러율도 많이 낮아졌다.
해당 포스팅은 패스트캠퍼스의 <파이썬을 활용한 시계열 데이터 분석 A-Z 올인원 패키지> 강의를 듣고 정리한 내용입니다
728×90
반응형
시계열 데이터 패턴 추출 (Feature Engineering) 1
시계열 데이터 분석을 위해서 사용하는 데이터는
https://github.com/cheonbi/OnlineTSA/tree/master/Data/BikeSharingDemand에서 다운받을 수 있다.
원본 데이터는 Kaggle에서 가져온 것으로
https://www.kaggle.com/c/bike-sharing-demand/overview
에서 다운받을 수 있다.
데이터 전처리 과정
String to DateTime Frequency 설정 시계열 데이터 요소 추출 (Count_trend, Count_seasonal) rolling() (Count_Day, Count_Week) 그룹화(temp_group) + 더미 변수(pd.get_dummies) 지연값 추출(count_lag1,2)
데이터에 관한 설명을 간단하게 하자면, 일단 X의 값을 가지고 자전거 수요량을 예측하기 위해서 만든 데이터 값이다.
Y와 관련된 값으로는 casual, registered, count가 있다.
casual : 자전거 서비스에 등록하지 않은 사람들의 자전거 사용량을 의미한다.
: 자전거 서비스에 등록하지 않은 사람들의 자전거 사용량을 의미한다. registered : 자전거 서비스에 등록한 사람들의 자전거 사용량을 의미한다.
: 자전거 서비스에 등록한 사람들의 자전거 사용량을 의미한다. count : 위의 두가지 수치를 더한 값으로, 총 자전거 사용량을 의미한다.
데이터 확인
1. String to Datetime
데이터를 불러오고 나서 확인하기 위해서 DataFrame을 출력한 결과이다.
가장 첫번째 Column인 datetime이 string형태로 되어있다.
시계열 데이터에서는 datetime에 입력된 형식의 datetime이라는 자료형이 있는데, 시계열 데이터 분석을 하기 위해서는 string으로 되어있는 datetime column의 데이터 형태를 datetime으로 변환해야 한다. 이때, pd.to_datetime() 함수를 이용한다.
# string to datetime if ‘datetime’ in raw_all.columns: raw_all[‘datetime’] = pd.to_datetime(raw_all[‘datetime’]) raw_all[‘DateTime’] = pd.to_datetime(raw_all[‘datetime’]) raw_all.info()
함수를 사용하고 난 뒤의 데이터 형식을 보면
(if문을 사용한 이유는 셀을 중복으로 실행하는 경우 Column이 너무 많아지거나 중복된 Column 이름으로 인해서 에러가 발생하는 것을 방지하기 위해서이다.)
.info()를 통해서 확인했을 때 가장 첫번째 Column의 데이터 형식이 datetime64[ns]인 것을 확인할 수 있다.
# set index as datetime column if raw_all.index.dtype == ‘int64’: raw_all.set_index(‘DateTime’, inplace=True) raw_all
이후에는 set_index() 함수를 통해서 datetime 형식으로 되어있는 데이터를 인덱스로 설정한다.
(inplace는 True일 경우에는 해당 변수에 저장되어 있는 내용을 변경한 값으로 저장하는 것,
False인 경우에는 변경된 내용은 별도로 두고 해당 변수는 상태를 그대로 유지하는 것)
인덱스 자체가 datetime의 값으로 표현되어 있는 것을 확인할 수 있다.
2. Frequency 설정
빈도(Frequency)란 사전적으로 “얼마나 자주”의 뜻을 가진 단어이지만, 시계열 데이터 분석에서 빈도는 분석에 주로 사용되는 시간의 단위라고 보면된다.
빈도를 설정하게 되면 위에서 우리가 인덱스로 설정한 datetime 데이터 형이 자동으로 맞춰준다.
이 기능을 하는 함수는 .asfreq(‘시간단위’)이다. 여기에서는 시간(Hour) 단위로 설정을 해주었다.
raw_all.asfreq(‘H’)
(시간은 ‘H’, 일(day)은 ‘D’, 주(Week)는 ‘W’ 등 한글자 알파벳을 통해서 시간의 빈도를 표현해준다. )
frequency를 시간으로 설정해 주고 DataFrame을 출력했을 때 확인할 수 있다.
.asfreq()를 통해서 빈도를 설정한다면 단순히 의미적으로만 시간의 단위를 설정해주고 끝나는 것인가?
그렇다면 굳이 컴퓨터가 그것을 알아야 할 이유는 무엇일까?
.asfreq()를 통해서 시간의 빈도를 설정하면 단순히 데이터 분석에서 주로 사용하는 시간의 단위를 설정해주는 것 뿐만 아니라,
데이터에 존재하지 않았던, 혹은 누락되었던 시간도 빠짐없이 새로 생긴다.
(다만, 이 때 새로 생성된 행에 대한 나머지 데이터들은 NaN값으로 채워진다. )
(다만, 이 때 새로 생성된 행에 대한 나머지 데이터들은 NaN값으로 채워진다. ) 새롭게 생성된 행들에서 NaN값을 채우기 위해서는 .asfreq()안의 method라는 인자를 통해서 채워줄 수 있다. method = ‘bfill’ : 뒤에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식 method = ‘ffill’ : 앞에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식
( .asfreq()의 method parameter 이외에도, .fillna() 등을 통해서 NaN 값들을 채울 수 있다. )
3. 시계열 데이터 요소 추출(Trend, Seasonal, Residual)
Seasonal Decompose
statsmodels.api(sm)을 이용해서
sm.tsa.seasonal_decompose() 함수를 이용하면 데이터 값을 Trend(경향), Seasonal(주기성), Residual(잔차)로 분리할 수 있다.
일단 기본적으로 Y값이 ‘count’ 특성이 어떤 형식으로 되어있는지 시각화를 통해서 확인한다.
# line plot of Y raw_all[[‘count’]].plot(kind=’line’, figsize=(20,6), linewidth=3, fontsize=20, xlim=(‘2012-01-01’, ‘2012-03-01’), ylim=(0,1000)) plt.title(‘Time Series of Target’, fontsize=20) plt.xlabel(‘Index’, fontsize=15) plt.ylabel(‘Demand’, fontsize=15) plt.show()
Y와 관련이 있는 데이터(casual, registered)들의 데이터와 count를 함께 시각화하여 확인해보자.
raw_all[[‘count’,’registered’,’casual’]].plot(kind=’line’, figsize=(20,6), linewidth=3, fontsize=20, xlim=(‘2012-01-01’, ‘2012-06-01’), ylim=(0,1000)) plt.title(‘Time Series of Target’, fontsize=20) plt.xlabel(‘Index’, fontsize=15) plt.ylabel(‘Demand’, fontsize=15) plt.show()
Model Parameter
seasonal_decompose() 에서 model parameter는 additive와 multiplicative 두가지를 입력으로 받는다.
additive : Trend + Seasonal + Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다.
: Trend + Seasonal + Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다. multiplicative : Trend X Seasonal X Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다.
일반적으로 additive가 많이 쓰이고, multiplicative 방식으로 시계열 요소를 분리하는 것은 분리하는 데이터가 백분율 등의 비율을 나타내는 경우에 사용된다고 한다 .
(하지만, 둘 중 어느 방식을 택하는 것은 두가지를 모두 시행하고 시각화를 하여 더욱 적절한 데이터 분리 방식을 선정해야 한다.)
raw_all[‘count’] – seasonal_decompose(model = ‘additive’)
# split data as trend + seasonal + residual plt.rcParams[‘figure.figsize’] = (14, 9) sm.tsa.seasonal_decompose(raw_all[‘count’], model=’additive’).plot() plt.show()
(plt.rcParams[‘figure.figsize’] = (14,9)는 시각화 그래프 설정이므로 시계열 데이터 분석과는 무관한 부분이다. )
위에서부터 기존의 count 데이터, Trend, Seasonal, Residual을 나타내는 그래프이다.
raw_all[‘ count’] – seasonal_decompose(model = ‘multiplicative’)
# split data as trend * seasonal * residual sm.tsa.seasonal_decompose(raw_all[‘count’], model=’multiplicative’).plot() plt.show()
model = ‘additive’에서 반환된 그래프와 비교를 해보았을 때,
Trend, Seasonal에 대한 그래프는 어느정도 유사하지만, Residual에 관해서는 확실히 multiplicative보다는 additive가 더 적절한 그래프를 보여주고 있다는 것을 볼 수 있다.
Reference :
패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
AI를 위한 시계열 데이터 전처리 Video
시계열 데이터를 통한 분석과 이를 활용한 AI 모델링에 대한 수요가 계속해서 증가하고 있습니다. MATLAB®은 이런 시계열 데이터에 대해 AI 모델링을 위한 데이터 분석과 전처리에 좋은 툴이며, 다양한 분야의 고객들께서 시계열 데이터를 활용한 AI 모델링을 통해 예측 모형을 개발 및 활용하고 계십니다. 본 세션에서는 이런 시계열 데이터를 활용하여 AI 모델링에 적용하기 위한 시계열 데이터의 전처리에 대해 소개드리고자 합니다. 구체적으로, 시계열 데이터에 대한 분석 및 AI모델링을 위한 레이블링, AI를 위한 데이터 전처리에서 생길 수 있는 여러가지 어려움을 해결한 MATLAB의 방식을 소개 드리고자 합니다.
시계열 데이터를 가지고 처음 AI모델링을 시작하시는 초보자 분들부터 이미 잘 사용하고 계신 숙련자까지 MATLAB 기반으로 AI 모델링을 위한 데이터 전처리에 대해 그 과정과 내용에 대해 상세히 전달드릴 예정입니다.
시계열 데이터 전처리 | 시계열 데이터 분석 기초 Part.1 #Python #파이썬 428 개의 새로운 답변이 업데이트되었습니다.
We are using cookies to give you the best experience on our website.
You can find out more about which cookies we are using or switch them off in settings.
Top 22 시계열 데이터 전처리 The 7 Detailed Answer
시계열 데이터 분석 기초 Part.1 #Python #파이썬
시계열 데이터 분석 기초 Part.1 #Python #파이썬
3. 데이터 전처리 — PseudoLab Tutorial Book
Article author: pseudo-lab.github.io
Reviews from users: 10805 Ratings
Ratings Top rated: 3.3
Lowest rated: 1
Summary of article content: Articles about 3. 데이터 전처리 — PseudoLab Tutorial Book 시계열 데이터를 지도학습 문제로 변환 하기 위해서는 예측 대상이 되는 타겟 변수와 예측할 때 사용하는 입력 변수 쌍으로 데이터를 가공해야 합니다. 또한 딥러닝 모델을 … …
Most searched keywords: Whether you are looking for 3. 데이터 전처리 — PseudoLab Tutorial Book 시계열 데이터를 지도학습 문제로 변환 하기 위해서는 예측 대상이 되는 타겟 변수와 예측할 때 사용하는 입력 변수 쌍으로 데이터를 가공해야 합니다. 또한 딥러닝 모델을 …
Table of Contents:
31 지도학습용 데이터 구축¶
32 데이터 스케일링¶
3. 데이터 전처리 — PseudoLab Tutorial Book
Read More
시계열 데이터에서 전처리하는 방법
Article author: ok-lab.tistory.com
Reviews from users: 2311 Ratings
Ratings Top rated: 3.5
Lowest rated: 1
Summary of article content: Articles about 시계열 데이터에서 전처리하는 방법 시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다. …
Most searched keywords: Whether you are looking for 시계열 데이터에서 전처리하는 방법 시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다. Contents 시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다. 결측치와 노이즈는 예측 성능을 떨어뜨리는 녀석들 중 하나이기에 사전에 전..Machine Learning, Deep Learning, Recommender Systems, NLP를 공부하고 있습니다. 이에 필요한 지식도 함께 다룹니다.
Table of Contents:
시계열 데이터에서 전처리하는 방법
티스토리툴바
시계열 데이터에서 전처리하는 방법
Read More
시계열 데이터 패턴 추출 (Feature Engineering) 1 – 데이터 사이언스 사용 설명서
Article author: dsbook.tistory.com
Reviews from users: 49041 Ratings
Ratings Top rated: 3.9
Lowest rated: 1
Summary of article content: Articles about 시계열 데이터 패턴 추출 (Feature Engineering) 1 – 데이터 사이언스 사용 설명서 에서 다운받을 수 있다. 데이터 전처리 과정. String to DateTime; Frequency 설정; 시계열 데이터 요소 추출 (Count_trend, Count_seasonal); rolling … …
Most searched keywords: Whether you are looking for 시계열 데이터 패턴 추출 (Feature Engineering) 1 – 데이터 사이언스 사용 설명서 에서 다운받을 수 있다. 데이터 전처리 과정. String to DateTime; Frequency 설정; 시계열 데이터 요소 추출 (Count_trend, Count_seasonal); rolling … 시계열 데이터 분석을 위해서 사용하는 데이터는 https://github.com/cheonbi/OnlineTSA/tree/master/Data/BikeSharingDemand에서 다운받을 수 있다. cheonbi/OnlineTSA Online Course of Time Series Analysis. C..데이터 사이언스 분야를 어떻게 공부하는지 알려주는 블로그
Table of Contents:
검색
시계열 데이터 패턴 추출 (Feature Engineering) 1
시계열 데이터 패턴 추출 (Feature Engineering) 1 – 데이터 사이언스 사용 설명서
Read More
시계열 데이터 전처리
Article author: velog.io
Reviews from users: 8056 Ratings
Ratings Top rated: 4.6
Lowest rated: 1
Summary of article content: Articles about 시계열 데이터 전처리 시간의 흐름에 따라 관측치가 변하는 시계열(Time Series) 데이터의 전처리. …
Most searched keywords: Whether you are looking for 시계열 데이터 전처리 시간의 흐름에 따라 관측치가 변하는 시계열(Time Series) 데이터의 전처리. 시간의 흐름에 따라 관측치가 변하는 시계열(Time Series) 데이터의 전처리
Table of Contents:
timeseries
결측치(Missing Values)
노이즈(Noise)
시계열 데이터 전처리
Read More
데이터 전처리 : 신호 처리 방법(푸리에 변환) – DACON
Article author: dacon.io
Reviews from users: 22443 Ratings
Ratings Top rated: 4.5
Lowest rated: 1
Summary of article content: Articles about 데이터 전처리 : 신호 처리 방법(푸리에 변환) – DACON zerojin입니다. Numpy에서 제공해주는 FFT 메소드를 통해 시계열 데이터 전처리를 방법을 소개드립니다. 푸리에 변환을 통해 기존 상태 관측 데이터에서 필요 … …
Most searched keywords: Whether you are looking for 데이터 전처리 : 신호 처리 방법(푸리에 변환) – DACON zerojin입니다. Numpy에서 제공해주는 FFT 메소드를 통해 시계열 데이터 전처리를 방법을 소개드립니다. 푸리에 변환을 통해 기존 상태 관측 데이터에서 필요 … Data Science Competition, datavisualization, DataScience, DataAnalyst, DataEngineer, DataScientist, MachineLearning, deeplearning, 데이터분석, 인공지능, 머신러닝, 딥러닝, 파이썬, 코드, 공유, AI, python, 통계, 수학, 경진대회알고리즘 | 정형 | 이상탐지 | 제어 | TaPR
Table of Contents:
데이터 전처리 : 신호 처리 방법(푸리에 변환) – DACON
Read More
See more articles in the same category here: toplist.giarevietnam.vn/blog.
시계열 데이터에서 전처리하는 방법
728×90 반응형 Contents 시계열(Time-Series) 데이터에서 전처리 과정에서 수행하는 일은 결측치를 제거하는 것과 노이즈(Noise)를 제거하는 것이다. 결측치와 노이즈는 예측 성능을 떨어뜨리는 녀석들 중 하나이기에 사전에 전처리 과정을 수행하여 처리한 후 작업을 수행하는 것이 옳다. 결측치 (Missing Values) 결측치는 말 그대로 값이 존재하지 않는 값을 의미한다. 예를 들어, 식당의 매출을 예측하는 경우 식당의 휴무일에는 매출이 존재하지 않을 것이다. 이와 같은 경우 이를 제거하고 예측하는 형태로 진행할 수 있을 것이다. 실제 데이터를 다룰 때 휴무일과 같은 경우로 데이터가 없을 수도 있고, 단순히 누락되었을 수도 있다. 일반적인 데이터의 구성에서는 큰 문제가 되지 않는다면 결측치를 제거하면 된다. 그러나, 시계열 데이터에서 결측치를 제거하게 되는 경우 그 시점의 평균과 분산의 왜곡을 가져오게 되고 이는 분석 결과에 치명적인 영향을 미칠 수 있다. 휴무일과 같은 데이터는 제거하면 되지만, 누락된 값인 경우 대체함으로써 평균과 분산에 왜곡을 가져오기 때문이다. 그러나 현실에서 접하는 대부분의 데이터는 항상 결측치가 발생한다. 특히 시계열은 시간의 흐름에 따라 그 시기에 데이터를 직접 수집하는 것이기 때문에 그 시기에 네트워크 이슈 혹은 센서 에러 등의 이유로 수집이 불가하면 결측치가 발생하게 되는 것이다. 시계열 데이터가 아닌 경우에는 일반적으로 평균이나 분산으로 대체하거나 결측치를 제거하면 그만이다. 그러나 시계열 데이터는 그렇게 처리할 경우 문제가 발생한다. 그렇다면 시계열 데이터에서의 결측치는 어떻게 처리할 수 있을까? 시계열 데이터는 시간의 흐름에 따라 데이터의 평균과 분산이 변하기에 이러한 특징을 잘 반영하는 방법론을 활용해야 성공적으로 결측치를 대체할 수 있다. 대체하는 방법은 다음과 같다. Last observation carried Forward (LOCF): 직전에 관측된 값으로 결측치를 대체 직전에 관측된 값으로 결측치를 대체 Next observation carried backwrd (NOCB): 직후에 관측된 값으로 결측치를 대체 직후에 관측된 값으로 결측치를 대체 Moving Average / Median: 직전 N의 time window의 평균치/중앙값으로 결측치를 대체 그러나 결측치 전후의 패턴이 변화하는 구간인 경우에는 이와 같은 방식으로 처리할 경우 문제가 발생한다. 예를 들어, 주가를 예측하는 경우 상승 구간이거나 하락 구간에 결측치가 존재할 때는 이전 값의 평균으로 대체하게 되면 실제 값과 차이가 발생하게 된다. 이런 경우에는 선형 보간법(Linear interpolation)을 통해 해당 값을 찾을 수 있다. 선형 보간법(Linear interpolation) 선형 보간법은 통계적으로 이미 구해진 데이터들로부터 t시점과 t+1시점 사이의 값을 유추하는 형태를 의미힌다. 예를 들어 끝점 $(x_0, y_0)$와 $(x_1, y_1)$가 주어졌을 때, 그 사이에 위치한 $(x,y)$의 값을 추정하기 위해 다음과 같은 수식을 세울 수 있다. \[ \frac{y-y_0}{x-x_0} = \frac{y_1 – y_0}{x_1 – x_0} \] \[ y= y_0 + (y_1 – y_0) \cdot \frac{x-x_0}{x_1 – x_0} \] 위 경우에는 선형 보간법에 대해서만 다루었으나, 선형 보간법 외에도 비선형, 스플라인 보간법 등 다양한 보간법이 존재한다. 필요에 따라 다양한 형태로 사잇값을 보간할 수 있다. 비선형 보간법은 선형 함수가 아닌 비선형 함수를 근사 함수로 사용하는 것을 의미하고, 스플라인(Spline) 보간법은 전체 구간을 근사하는 것이 아닌, 소구간으로 분할하여 보간하는 방법을 의미한다. 좌: Linear interpolation, 우: Linear Polinomial 만약 누락된 값이 너무 많은 경우에는 위와 같은 방법으로 처리를 할 수 없다. 이때는 모델링을 통해 해당 부분을 예측하는 형태로 진행하여야 한다. 일반적인 데이터라면 기존에 수집된 데이터로 결측치를 잘 설명할 수 있으나, 시계열 데이터는 시간에 따라 변화하기에 이를 모델링하는 것은 어렵다. 그러나 최근에는 GAN에 기반한 시계열 생성 알고리즘으로 이 부분을 채우고자 하는 연구가 많이 진행되고 있다. 노이즈(Noise) 노이즈는 잡음을 의미하며, 의도하지 않은 데이터의 왜곡을 불러오는 모든 것들을 칭한다. 예를 들어, 음성 처리의 경우 주변의 소음으로 인해 음성 인식이 제대로 되지 않는다면 이때 소음을 노이즈로 판단한다. 시계열 데이터에서는 원래 분포를 왜곡하는 모든 요인을 칭한다. 최근 주식 시장에서는 코로나 사태로 인해 주가가 엄청나게 하락을 하게 되었다. 이 때 해당 부분을 노이즈로 볼 것인지, 아닌지를 판단함에 따라 제거할수도, 제거하지 않을수도 있다. 시계열 데이터에서 노이즈를 제거하는 방법을 Denosing이라고 한다. 가장 간단한 Denosing 방법으로는 Moving Average가 있다. Moving Average는 평균값으로 관측치를 대체하는 방식이며, 이를 통해 이상하게 튀는 값을 평할화(Smoothing)할 수 있다. 노이즈가 정말 많은 환경에서는 노이즈 자체가 평균이 되어버리는 경우가 있으나, 노이즈가 간혹 발생하는 경우에는 매우 효과적이다. 그렇다면 노이즈가 많은 환경에는 어떻게 처리를 해야할까? 노이즈가 많은 환경에서는 노이즈를 Smoothing 혹은 Filtering 하는 법이 있다. 현재 시계열에 발생하는 노이즈가 어떤 특정한 분포를 따른다고 가정하고 해당 분포의 값을 시계열에서 제거하는 형태로 진행한다. \[ x_{n+1} + \xi = Ax_{n}\] 여기서 $\xi$가 어떤 특정한 분포를 따른다고 가정하고, 이를 근사한 값을 제거함으로써 원래 값을 복원할 수 있다. 따라서, $Ax_n$를 구한다음 $\xi$를 빼서 원래 시계열 구조를 찾는 것이다. 특정한 분포는 일반적으로 가우시안(Gaussian) 분포를 많이 사용한다. 필터링(Filtering) 노이즈를 제거하는 대표적인 필터링 방법은 가우시안 필터링(Gaussian Filtering), 쌍방 필터(Bilateral Filter), 칼만 필터(Kalman Filter)가 있다. 가우시안 필터링은 노이즈가 정규분포를 따른다고 가정하는 것을 의미하고, 쌍방 필터는 변곡점이 큰 지점을 뭉개버리는 특징을 갖는 가우시안 필터링의 단점을 보완해 데이터의 원 분포에 따라 발생하는 엣지(Edge)들을 더 잘 보존하는 방법이다. 가우시안 필터링(Gaussian Filtering) 가우시안 필터링은 시계열 데이터 뿐만 아니라 이미지 처리에서도 많이 사용하는 Filter 중 하나이며, 수식은 다음과 같다. \[ G(x,y) = \frac{1}{2 \pi \sigma^2} \exp(-\frac{x^2 + y^2}{2 \sigma^2}) \] 위 수식을 살펴보면 가우시안 필터에서 결정해야할 파라미터는 $\sigma$이다. 일반적으로 $1\sigma$는 68%, $2\sigma$는 95%, $3\sigma$는 99.7%를 설명한다고 알려져있기 때문에 $3\sigma$까지 고려할 때 정확도가 가장 높다고 한다. 경제학에서는 기본적으로 세상의 모든 현상을 가우시안 분포로 설명한다. 그러나 이러한 분포는 주식과 같은 경제 분야에서는 전혀 들어맞지 않는 상황이 발생할 수 있다. 일반적으로 주식 시장에서는 극단적인 경우가 많이 발생하기에 이러한 경우를 팻 테일(Fat Tail)이라 부른다. 이는 정규분포의 양 끝 모양이 더 뚱뚱한 것을 의미한다. 쌍방 필터(Bilateral Filter) 가우시안 필터링은 노이즈를 제거하는데 있어 효과적이지만, 경계성이 뭉개지는 현상이 있다. 이러한 문제점을 보완한 필터링이 바로 쌍방 필터링이며, 수식은 다음과 같다. \[ \text{BF}[I]_p = \frac{1}{W_p} \sum_{q\in S} G_{\sigma_s} (||p-q||) \cdot G_{\sigma_r} (||I_p – I_q||) I_q \] 칼만 필터(Kalmal Filter) 칼만 필터는 잡음이 포함된 과거 측정값에서 현재 상태의 결합분포를 추정하는 알고리즘이다. 어떠한 정보가 있을 때 해당 데이터는 mixture 모델임(GMM과 같이)을 가정한다. 즉, 다른 분포들의 결합이라는 것을 가정한다. 일반화된 분포를 가정하는 것이 아닌 데이터의 특정에 맞는 분포를 모델링할 수 있어 상당히 많이 사용되며 특히 이미지 트래킹 분야에서 많이 사용되는 필터링 중 하나이다. 수식은 다음과 같다. \[ \mu_{\text{new}} = \frac{\mu_2 \sigma^2_1 + \mu_1 \sigma^2_2}{\sigma^2_1 + \sigma^2_2} \] \[ \sigma^2_{\text{new}} = \frac{\sigma^2_1 \sigma^2_2}{\sigma^2_1 + \sigma^2_2} \] 728×90
시계열 데이터 패턴 추출 (Feature Engineering) 1
시계열 데이터 분석을 위해서 사용하는 데이터는 https://github.com/cheonbi/OnlineTSA/tree/master/Data/BikeSharingDemand에서 다운받을 수 있다. 원본 데이터는 Kaggle에서 가져온 것으로 https://www.kaggle.com/c/bike-sharing-demand/overview 에서 다운받을 수 있다. 데이터 전처리 과정 String to DateTime Frequency 설정 시계열 데이터 요소 추출 (Count_trend, Count_seasonal) rolling() (Count_Day, Count_Week) 그룹화(temp_group) + 더미 변수(pd.get_dummies) 지연값 추출(count_lag1,2) 데이터에 관한 설명을 간단하게 하자면, 일단 X의 값을 가지고 자전거 수요량을 예측하기 위해서 만든 데이터 값이다. Y와 관련된 값으로는 casual, registered, count가 있다. casual : 자전거 서비스에 등록하지 않은 사람들의 자전거 사용량을 의미한다. : 자전거 서비스에 등록하지 않은 사람들의 자전거 사용량을 의미한다. registered : 자전거 서비스에 등록한 사람들의 자전거 사용량을 의미한다. : 자전거 서비스에 등록한 사람들의 자전거 사용량을 의미한다. count : 위의 두가지 수치를 더한 값으로, 총 자전거 사용량을 의미한다. 데이터 확인 1. String to Datetime 데이터를 불러오고 나서 확인하기 위해서 DataFrame을 출력한 결과이다. 가장 첫번째 Column인 datetime이 string형태로 되어있다. 시계열 데이터에서는 datetime에 입력된 형식의 datetime이라는 자료형이 있는데, 시계열 데이터 분석을 하기 위해서는 string으로 되어있는 datetime column의 데이터 형태를 datetime으로 변환해야 한다. 이때, pd.to_datetime() 함수를 이용한다. # string to datetime if ‘datetime’ in raw_all.columns: raw_all[‘datetime’] = pd.to_datetime(raw_all[‘datetime’]) raw_all[‘DateTime’] = pd.to_datetime(raw_all[‘datetime’]) raw_all.info() 함수를 사용하고 난 뒤의 데이터 형식을 보면 (if문을 사용한 이유는 셀을 중복으로 실행하는 경우 Column이 너무 많아지거나 중복된 Column 이름으로 인해서 에러가 발생하는 것을 방지하기 위해서이다.) .info()를 통해서 확인했을 때 가장 첫번째 Column의 데이터 형식이 datetime64[ns]인 것을 확인할 수 있다. # set index as datetime column if raw_all.index.dtype == ‘int64’: raw_all.set_index(‘DateTime’, inplace=True) raw_all 이후에는 set_index() 함수를 통해서 datetime 형식으로 되어있는 데이터를 인덱스로 설정한다. (inplace는 True일 경우에는 해당 변수에 저장되어 있는 내용을 변경한 값으로 저장하는 것, False인 경우에는 변경된 내용은 별도로 두고 해당 변수는 상태를 그대로 유지하는 것) 인덱스 자체가 datetime의 값으로 표현되어 있는 것을 확인할 수 있다. 2. Frequency 설정 빈도(Frequency)란 사전적으로 “얼마나 자주”의 뜻을 가진 단어이지만, 시계열 데이터 분석에서 빈도는 분석에 주로 사용되는 시간의 단위라고 보면된다. 빈도를 설정하게 되면 위에서 우리가 인덱스로 설정한 datetime 데이터 형이 자동으로 맞춰준다. 이 기능을 하는 함수는 .asfreq(‘시간단위’)이다. 여기에서는 시간(Hour) 단위로 설정을 해주었다. raw_all.asfreq(‘H’) (시간은 ‘H’, 일(day)은 ‘D’, 주(Week)는 ‘W’ 등 한글자 알파벳을 통해서 시간의 빈도를 표현해준다. ) frequency를 시간으로 설정해 주고 DataFrame을 출력했을 때 확인할 수 있다. .asfreq()를 통해서 빈도를 설정한다면 단순히 의미적으로만 시간의 단위를 설정해주고 끝나는 것인가? 그렇다면 굳이 컴퓨터가 그것을 알아야 할 이유는 무엇일까? .asfreq()를 통해서 시간의 빈도를 설정하면 단순히 데이터 분석에서 주로 사용하는 시간의 단위를 설정해주는 것 뿐만 아니라, 데이터에 존재하지 않았던, 혹은 누락되었던 시간도 빠짐없이 새로 생긴다. (다만, 이 때 새로 생성된 행에 대한 나머지 데이터들은 NaN값으로 채워진다. ) (다만, 이 때 새로 생성된 행에 대한 나머지 데이터들은 NaN값으로 채워진다. ) 새롭게 생성된 행들에서 NaN값을 채우기 위해서는 .asfreq()안의 method라는 인자를 통해서 채워줄 수 있다. method = ‘bfill’ : 뒤에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식 method = ‘ffill’ : 앞에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식 ( .asfreq()의 method parameter 이외에도, .fillna() 등을 통해서 NaN 값들을 채울 수 있다. ) 3. 시계열 데이터 요소 추출(Trend, Seasonal, Residual) Seasonal Decompose statsmodels.api(sm)을 이용해서 sm.tsa.seasonal_decompose() 함수를 이용하면 데이터 값을 Trend(경향), Seasonal(주기성), Residual(잔차)로 분리할 수 있다. 일단 기본적으로 Y값이 ‘count’ 특성이 어떤 형식으로 되어있는지 시각화를 통해서 확인한다. # line plot of Y raw_all[[‘count’]].plot(kind=’line’, figsize=(20,6), linewidth=3, fontsize=20, xlim=(‘2012-01-01’, ‘2012-03-01’), ylim=(0,1000)) plt.title(‘Time Series of Target’, fontsize=20) plt.xlabel(‘Index’, fontsize=15) plt.ylabel(‘Demand’, fontsize=15) plt.show() Y와 관련이 있는 데이터(casual, registered)들의 데이터와 count를 함께 시각화하여 확인해보자. raw_all[[‘count’,’registered’,’casual’]].plot(kind=’line’, figsize=(20,6), linewidth=3, fontsize=20, xlim=(‘2012-01-01’, ‘2012-06-01’), ylim=(0,1000)) plt.title(‘Time Series of Target’, fontsize=20) plt.xlabel(‘Index’, fontsize=15) plt.ylabel(‘Demand’, fontsize=15) plt.show() Model Parameter seasonal_decompose() 에서 model parameter는 additive와 multiplicative 두가지를 입력으로 받는다. additive : Trend + Seasonal + Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다. : Trend + Seasonal + Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다. multiplicative : Trend X Seasonal X Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다. 일반적으로 additive가 많이 쓰이고, multiplicative 방식으로 시계열 요소를 분리하는 것은 분리하는 데이터가 백분율 등의 비율을 나타내는 경우에 사용된다고 한다 . (하지만, 둘 중 어느 방식을 택하는 것은 두가지를 모두 시행하고 시각화를 하여 더욱 적절한 데이터 분리 방식을 선정해야 한다.) raw_all[‘count’] – seasonal_decompose(model = ‘additive’) # split data as trend + seasonal + residual plt.rcParams[‘figure.figsize’] = (14, 9) sm.tsa.seasonal_decompose(raw_all[‘count’], model=’additive’).plot() plt.show() (plt.rcParams[‘figure.figsize’] = (14,9)는 시각화 그래프 설정이므로 시계열 데이터 분석과는 무관한 부분이다. ) 위에서부터 기존의 count 데이터, Trend, Seasonal, Residual을 나타내는 그래프이다. raw_all[‘ count’] – seasonal_decompose(model = ‘multiplicative’) # split data as trend * seasonal * residual sm.tsa.seasonal_decompose(raw_all[‘count’], model=’multiplicative’).plot() plt.show() model = ‘additive’에서 반환된 그래프와 비교를 해보았을 때, Trend, Seasonal에 대한 그래프는 어느정도 유사하지만, Residual에 관해서는 확실히 multiplicative보다는 additive가 더 적절한 그래프를 보여주고 있다는 것을 볼 수 있다. Reference : 패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
시계열 데이터 전처리 결과 확인 : pandas Series
시계열 데이터 전처리 결과 확인 : pandas Series API를 이용하거나, 직접 수집해 온 시계열 데이터에서 새로운 정보를 얻기 위해 파이썬 데이터 분석을 따라해 보고 있는 중입니다. 이번 포스팅에서는 파이썬 데이터 분석에서 빼놓을 수 없는 판다스 라이브러리를 이해해 보겠습니다. 데이터 분석에 필요한 데이터만 남기고 나머지를 날려버리는 데이터 전처리 과정을 간략하게 정리해본 후 그 결과로 나온 리스트 형태의 데이터를 pandas를 이용하여 표로 만들어보는 것이 목표입니다. 글의 순서 판다스 라이브러리 (pandas library) 업비트 API로 받아온 비트코인 데이터 전처리 과정과 결과 pandas 라이브러리로 시간에 따른 비트코인 가격 표 만들기 판다스 라이브러리 (pandas library) 판다스 라이브러리는 파이썬 데이터 분석에서 빼놓을 수 없는 유용한 분석 도구입니다. 데이터를 이해하기 위해서 주로 어떤 방법을 쓰고 계시나요? 대부분 그래프로 그려보거나, 표로 정리해보는 것일 겁니다. 표를 영어로는 테이블(table)이라고 합니다. 그래프나 테이블을 담당하는 대표적인 파이썬 패키지는 matplotlib와 pandas입니다. matplotlib 패키지를 이용하여 그래프를 그릴 수 있듯, 판다스(pandas) 패키지로는 테이블을 만들 수 있습니다. 그것도 눈에 잘 들어오는 형태로 말입니다. 여러차례 말씀드렸지만 파이썬에서 쓰는 패키지라는 용어는 다른 프로그래밍 언어의 라이브러리와 같은 의미입니다. panads는 panel datas의 줄임말이며, 파이썬 데이터 분석에서 무척 많이 사용되는 라이브러리입니다. 판다스에서 제공하는 데이터 구조는 한 줄로 길게 줄지어놓은 1차원 배열 형태와 테이블 모양의 2차원 배열 행태의 2가지입니다. 1차원 배열 형태를 Series, 2차원 배열 형태를 DataFrame 이라고 부릅니다. 1차원 배열 형태는 리스트라는 파이썬 자료구조와 잘 대응됩니다. 판다스 라이브러리도 matplotlib 패키지처럼 기능이 방대합니다. 판다스만 전문적으로 다루는 책이 있을 정도입니다. 여기서는 데이터 분석에 유용한 기능 위주로 연습해 보겠습니다. 판다스의 Series는 리스트라는 자료구조와 대응된다는 사실을 기억해 주시기 바랍니다. 지난 포스팅에서 API로 받아온 데이터를 전처리 하고 난 결과가 바로 리스트 형태였습니다. 업비트 API로 받아온 시계열 데이터 전처리 과정과 결과 업비트 API를 이용하여 비트코인 가격 데이터를 수집한 후 전처리 과정을 알아봤는데요. 판다스 라이브러리를 사용하면 그래프가 아니라 테이블로 데이터를 확인할 수 있습니다. 일단 비트코인 가격 데이터가 파이썬 자료구조 중 리스트 모양으로 나오는 과정을 정리해보겠습니다. (1) 업비트 API 분석하기 이 포스팅에서 원하는 시계열 데이터는 지난 20일간의 코인 시세입니다. 시계열 데이터 그래프에서 데이터를 비교하기 위하여 비트코인과 이더리움의 가격을 가져올 예정입니다. 아래의 API에서 market과, count를 바꾸면 코인 종류와 기간이 바뀝니다. https://api.upbit.com/v1/candles/days?market=KRW-BTC&count=2 (2) 업비트 API를 포함하는 파이썬 함수 만들기 함수는 프로그램을 확장하고, 코드를 깔끔하게 만드는데 아주 중요한 요소입니다. 시계열 데이터를 수집하기 위해 API가 포함된 파이썬 함수를 만듭니다. 이때 함수에 넘겨주는 파라미터는 코인의 종류와 가격을 수집하는 기간입니다. (3) 업비트 API로 가져온 데이터 확인 업비트 API를 이용하여 받아온 코인가격 데이터는 리스트 안에 딕셔너리가 들어있는 [ { }, { }, … { } ] 형태입니다. 각 딕셔너리 { }에는 시간 데이터와 코인 가격 데이터 등이 들어있습니다. (4) 업비트 API로 가져온 데이터 전처리 시간에 따른 코인 가격이라는 시계열 데이터를 추출하기 위해서는 딕셔너리로부터 데이터를 추출해내야 합니다. 빈 리스트를 만들어 놓고 for 반복문으로 리스트 안에 있는 딕셔너리를 하나씩 훑으면서, 미리 정해놓은 key를 만날 경우, key에 대응되는 값을 리스트에 덧붙이는 방법을 사용합니다. 이 방법으로 시간을 담아놓은 리스트와 코인 가격을 담아놓은 리스트를 만들 수 있습니다. (5) 데이터 전처리 결과 확인 데이터 전처리 결과는 시간 리스트와 코인 가격 리스트입니다. 데이터전처리01은 (1)~(5) 까지의 과정을 구현한 파이썬 코드입니다. 코드 실행결과도 연달아 나타내었습니다. 코드의 print() 부분을 유심히 봐 주시기 바랍니다. 실습코드 : 시계열 데이터 추출01 import requests import json import matplotlib.pyplot as plt #(1) UPbit API 분석하기 #(2) UPbit API를 포함하는 파이썬 함수 만들기 def get_coin_price(ticker,n_candle): url = (“https://api.upbit.com/v1/candles/days?market=%s&count=%d” %(ticker, n_candle)) print(url) raw_resp = requests.get(url) response = raw_resp.json() return response #(3) UPbit API로 데이터 가져온 후 확인 coin_price = get_coin_price(“KRW-BTC”,2) print(coin_price) #(4) UPbit API로 가져온 데이터 전처리 date = [] price = [] for i in range(0,len(coin_price)): date.append(coin_price[len(coin_price)-1-i][“candle_date_time_kst”]) price.append(coin_price[len(coin_price)-1-i][“trade_price”]) #(5) 데이터 전처리 결과 print(“— Data 전처리 결과 —“) print(date) print(price) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import requests import json import matplotlib . pyplot as plt #(1) UPbit API 분석하기 #(2) UPbit API를 포함하는 파이썬 함수 만들기 def get_coin_price ( ticker , n_candle ) : url = ( “https://api.upbit.com/v1/candles/days?market=%s&count=%d” % ( ticker , n_candle ) ) print ( url ) raw_resp = requests . get ( url ) response = raw_resp . json ( ) return response #(3) UPbit API로 데이터 가져온 후 확인 coin_price = get_coin_price ( “KRW-BTC” , 2 ) print ( coin_price ) #(4) UPbit API로 가져온 데이터 전처리 date = [ ] price = [ ] for i in range ( 0 , len ( coin_price ) ) : date . append ( coin_price [ len ( coin_price ) – 1 – i ] [ “candle_date_time_kst” ] ) price . append ( coin_price [ len ( coin_price ) – 1 – i ] [ “trade_price” ] ) #(5) 데이터 전처리 결과 print ( “— Data 전처리 결과 —” ) print ( date ) print ( price ) pandas 라이브러리로 시간에 따른 비트코인 가격 표 만들기 데이터 전처리 결과로 2개의 리스트가 나왔습니다. pandas 라이브러리를 사용해서 얼마나 가독성 좋게 데이터를 보여주는지 확인해보겠습니다. pandas 라이브러리를 사용하기 위해서는 먼저 pandas 라이브러리를 설치해야 합니다. 지금까지 계속 사용해오고 있는 replit 이라는 온라인 프로그래밍 환경에서는 패키지를 검색한 후 install 하면 되고, 윈도우나 맥 환경에서는 아래와 같이 설치합니다. 이 부분은 지난 포스팅 ‘업비트 REST API를 이용한 비트코인 가격 추출 파이썬 프로그래밍’을 참고하시기 바랍니다. pip install panas 많은 데이터 전문가들은 pandas 라이브러리를 pd라는 별명을 써서 짧게 부릅니다. pandas의 Series 라는 클래스는 1차원 배열 형태의 데이터를 사용하는데, 1차원 배열의 각 값(values)에 인덱스(index)를 부여합니다. 아래는 srs라는 변수에 pandas의 Series를 이용하여 값을 담아두는 방법이며, 인덱스를 date로 부여한 경우입니다. srs의 값과 인덱스는 각각 print(srs.values), print(srs.index)로 확인할 수 있습니다. pandas에 있는 Series를 사용하는 방법은 pandas.Series인데, 아래의 pd.Series는 pandas를 pd라는 별명으로 쓴다는 import pandas as pd를 코드 시작부분에 선언해놨을 경우 사용할 수 있습니다. srs1 = pd.Series(price, date) srs가 어떤 모양의 테이블인지를 확인하려면 늘 쓰던 print(srs)가 좋은 방법입니다. 인덱스를 부여하지 않았을 때는 0, 1, 2, 3 과 같은 숫자가 자동으로 부여됩니다. pandas.Series를 이용하면서 별도로 인덱스를 부여하지 않고, 자동으로 인덱를 부여하려면 아래처럼 pd.Series(price,date) 대신 pd.Series(price)를 사용하시면 됩니다. srs2 = pd.Series(price) 여기까지 pandas 자료구조 중 Series를 이용하는 방법을 알아보았습니다. 데이터전처리02 코드를 실행하면 실행결과에서처럼 pandas를 이용한 전처리 결과를 확인하실 수 있습니다. 데이터전처리02 코드에 있는 print문 내부의 “ ”는 빈 줄을 하나 삽입하라는 의미입니다. 출력된 결과물의 가독성을 높이기 위해 빈 줄을 추가해보았습니다. 덱스를 부여하지 않고, 자동으로 인덱를 부여하려면 아래처럼 pd.Series(price,date) 대신 pd.Series(price)를 사용하시면 됩니다. 실습코드 : 시계열 데이터 추출01 import requests import json import pandas as pd import matplotlib.pyplot as plt #(1) UPbit API 분석하기 #(2) UPbit API를 포함하는 파이썬 함수 만들기 def get_coin_price(ticker,n_candle): url = (“https://api.upbit.com/v1/candles/days?market=%s&count=%d” %(ticker, n_candle)) raw_resp = requests.get(url) response = raw_resp.json() return response #(3) UPbit API로 데이터 가져온 후 확인 coin_price = get_coin_price(“KRW-BTC”,2) #(4) UPbit API로 가져온 데이터 전처리 date = [] price = [] for i in range(0,len(coin_price)): date.append(coin_price[len(coin_price)-1-i][“candle_date_time_kst”]) price.append(coin_price[len(coin_price)-1-i][“trade_price”]) #(5) 데이터 전처리 결과 print(“– Data 전처리 결과 –“) print(date) print(price) #(6) pandas를 이용한 전처리 결과 확인 srs1 = pd.Series(price,date) srs1 = pd.Series(price) print(” ” + “– pandas를 이용한 전처리 결과 확인 –“) print(“index를 date로 부여할 경우 “) print(srs1) print(” ” + “index를 자동으로 부여할 경우 “) print(srs2) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import requests import json import pandas as pd import matplotlib . pyplot as plt #(1) UPbit API 분석하기 #(2) UPbit API를 포함하는 파이썬 함수 만들기 def get_coin_price ( ticker , n_candle ) : url = ( “https://api.upbit.com/v1/candles/days?market=%s&count=%d” % ( ticker , n_candle ) ) raw_resp = requests . get ( url ) response = raw_resp . json ( ) return response #(3) UPbit API로 데이터 가져온 후 확인 coin_price = get_coin_price ( “KRW-BTC” , 2 ) #(4) UPbit API로 가져온 데이터 전처리 date = [ ] price = [ ] for i in range ( 0 , len ( coin_price ) ) : date . append ( coin_price [ len ( coin_price ) – 1 – i ] [ “candle_date_time_kst” ] ) price . append ( coin_price [ len ( coin_price ) – 1 – i ] [ “trade_price” ] ) #(5) 데이터 전처리 결과 print ( “– Data 전처리 결과 –” ) print ( date ) print ( price ) #(6) pandas를 이용한 전처리 결과 확인 srs1 = pd . Series ( price , date ) srs1 = pd . Series ( price ) print ( ” ” + “– pandas를 이용한 전처리 결과 확인 –” ) print ( “index를 date로 부여할 경우 ” ) print ( srs1 ) print ( ” ” + “index를 자동으로 부여할 경우 ” ) print ( srs2 ) 데이터전처리02 실행결과 — Data 전처리 결과 — [‘2022-06-25T09:00:00’, ‘2022-06-26T09:00:00’] [27832000.0, 27697000.0] — pandas를 이용한 전처리 결과 확인 — index를 date로 부여할 경우 2022-06-25T09:00:00 27832000.0 2022-06-26T09:00:00 27697000.0 dtype: float64 index를 자동으로 부여할 경우 0 27832000.0 1 27697000.0 dtype: float64 마치며 … API를 이용하거나, 직접 수집해 온 데이터에서 새로운 정보를 얻기 위해 파이썬 데이터 분석을 따라해 보고 있는 중입니다. 이번 포스팅에서는 파이썬 데이터 분석에서 빼놓을 수 없는 pandas 라이브러리를 활용해 보았습니다. panads는 panel datas의 줄임말이며, 파이썬 데이터 분석에서 무척 많이 사용되는 라이브러리입니다. matplotlib 라이브러리를 이용하여 그래프를 그릴 수 있듯, 판다스(pandas) 라이브러리로는 테이블을 만들 수 있습니다. 판다스에서 제공하는 데이터 구조는 한 줄로 길게 줄지어놓은 1차원 배열 형태와 테이블 모양의 2차원 배열 행태의 2가지입니다. 1차원 배열 형태를 Series, 2차원 배열 형태를 DataFrame 이라고 부릅니다. 1차원 배열 형태는 리스트라는 파이썬 자료구조와 잘 대응됩니다. 이번 포스팅에서는 pandas의 Series를 이용하여 전처리 결과를 확인하였습니다. 다음 포스팅에서는 pandas의 DataFrame에 대해 알아보겠습니다. 함께 참고하면 더 좋은 글 : 1. 파이썬 프로그래밍 시작하기 (1) 온라인 프로그래밍 환경 replit 2. 업비트 API로 이해해보는 REST API 3. 업비트 REST API를 이용한 비트코인 가격 추출 파이썬 프로그래밍 4. 업비트 시계열 데이터 가시화를 위한 전처리 5. 시계열 데이터 가시화 (2) 보고서용 파이썬 그래프 만들기 6. 파이썬 데이터 분석! 데이터 분석을 위한 코딩언어 파이썬 7. 알아두면 좋을 컴퓨터 작동원리. 폰 노이만 아키텍처 참고자료 UPbit(2020),일(Day) 캔들
So you have finished reading the 시계열 데이터 전처리 topic article, if you find this article useful, please share it. Thank you very much. See more: 파이썬 시계열 데이터 전처리, 시계열 데이터 머신러닝 전처리, 시계열 데이터 노이즈 제거, R 시계열 데이터 전처리, 시계열 데이터 트렌드, 시계열 데이터 학습, 시간 데이터 전처리, 시계열 데이터 결측치 처리
키워드에 대한 정보 시계열 데이터 전처리
다음은 Bing에서 시계열 데이터 전처리 주제에 대한 검색 결과입니다. 필요한 경우 더 읽을 수 있습니다.
이 기사는 인터넷의 다양한 출처에서 편집되었습니다. 이 기사가 유용했기를 바랍니다. 이 기사가 유용하다고 생각되면 공유하십시오. 매우 감사합니다!
사람들이 주제에 대해 자주 검색하는 키워드 인공지능 10-02/ 시계열데이터의 특징과 전처리 방법
- 동영상
- 공유
- 카메라폰
- 동영상폰
- 무료
- 올리기
인공지능 #10-02/ #시계열데이터의 #특징과 #전처리 #방법
YouTube에서 시계열 데이터 전처리 주제의 다른 동영상 보기
주제에 대한 기사를 시청해 주셔서 감사합니다 인공지능 10-02/ 시계열데이터의 특징과 전처리 방법 | 시계열 데이터 전처리, 이 기사가 유용하다고 생각되면 공유하십시오, 매우 감사합니다.